
Облачные хранилища данных
В последние несколько лет мы наблюдаем быстрый рост использования облачных хранилищ данных (а также парадигмы «сначала хранилище»). Двумя популярными облачными платформами DWH являются BigQuery и Snowflake. Посмотрите на диаграмму ниже, чтобы увидеть их эволюцию с течением времени.
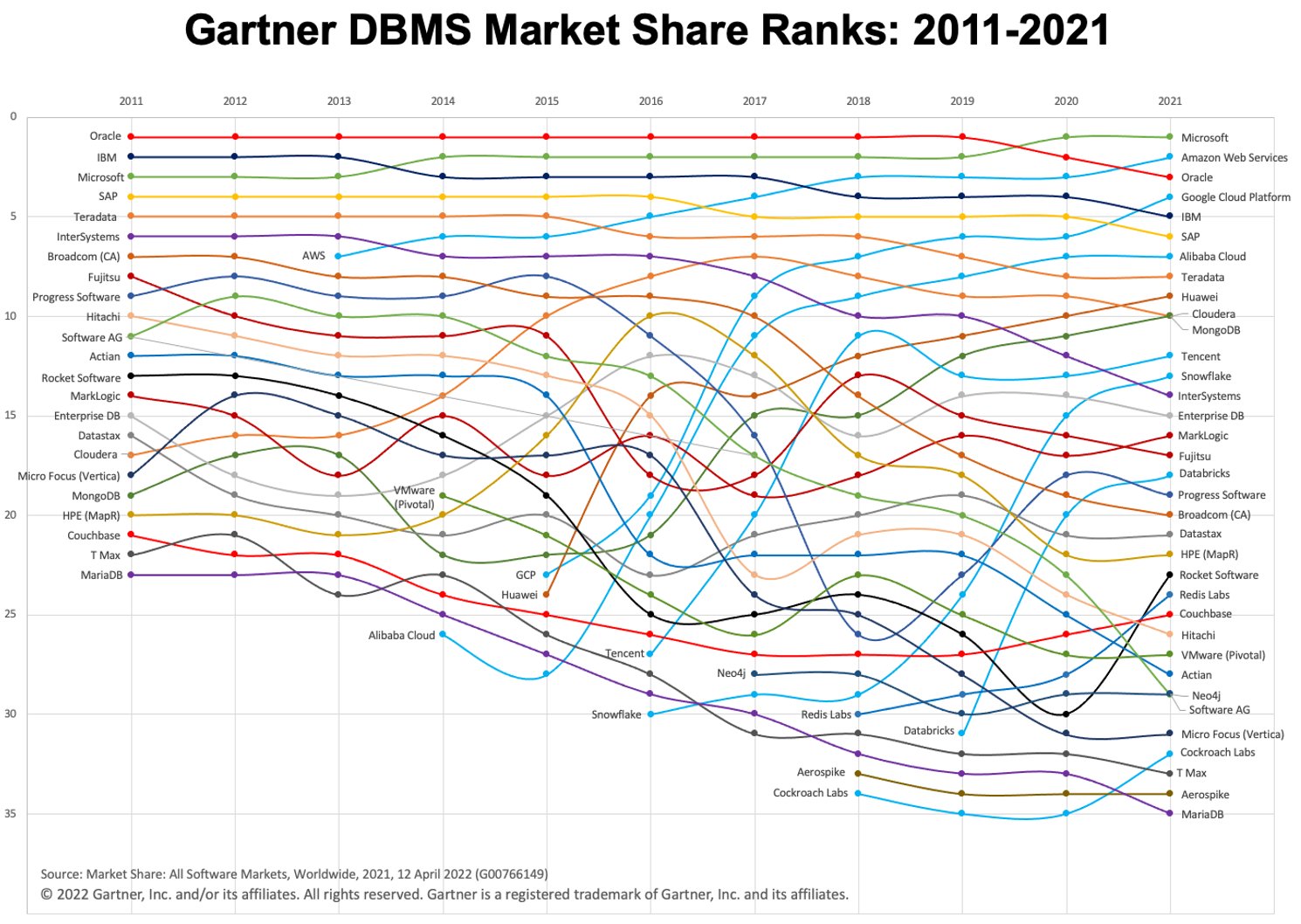 Изображение: Gartner через Адама Ронтала (@aronthal) в [Twitter] (https://twitter.com/ARonthal/status/1514595630072619014/photo/1).
Изображение: Gartner через Адама Ронтала (@aronthal) в [Twitter] (https://twitter.com/ARonthal/status/1514595630072619014/photo/1).
BigQuery, занимающий 4-е место в 2021 году, представляет собой полностью управляемую бессерверную службу хранилища данных, предлагаемую Google Cloud Platform (GCP). Он позволяет легко и масштабируемо анализировать петабайты данных и уже давно известен своей простотой использования и отсутствием обслуживания.
Snowflake — аналогичная услуга, предлагаемая компанией Snowflake Inc. Одно из принципиальных отличий состоит в том, что Snowflake позволяет размещать экземпляр либо в Amazon Web Services (AWS), Azure (Microsoft), либо в GCP (Google). Это большое преимущество, если вы уже работаете в среде, отличной от GCP.
Экспорт и загрузка данных
Иногда бывает необходимо или желательно скопировать данные из среды BigQuery в среду Snowflake. Давайте посмотрим и разберем различные логические шаги, необходимые для правильного перемещения этих данных, поскольку ни один из конкурирующих сервисов не имеет встроенной функции, позволяющей легко это сделать. Для нашего примера мы предположим, что наша целевая среда Snowflake размещена на AWS.
Пошаговая процедура
Чтобы перенести данные из BigQuery в Snowflake (AWS), выполните следующие действия:
Определите таблицу или запрос и выполните
EXPORT DATA OPTIONSзапрос для экспорта в Google Cloud Storage (GCS).Запустите скрипт на виртуальной машине или локальном компьютере, чтобы скопировать данные GCS на внутреннюю сцену Snowflake. Мы также могли бы читать прямо из GCS с интеграцией хранилища, но это требует еще одного уровня конфигурации безопасного доступа (что может быть предпочтительнее для вашего варианта использования).
Вручную сгенерируйте
CREATE TABLEDDL с правильными типами данных столбцов и выполните в Snowflake.Выполните запрос
COPYв Snowflake для импорта промежуточных файлов.При необходимости очистить (удалить) временные данные в GCP и Internal Stage.
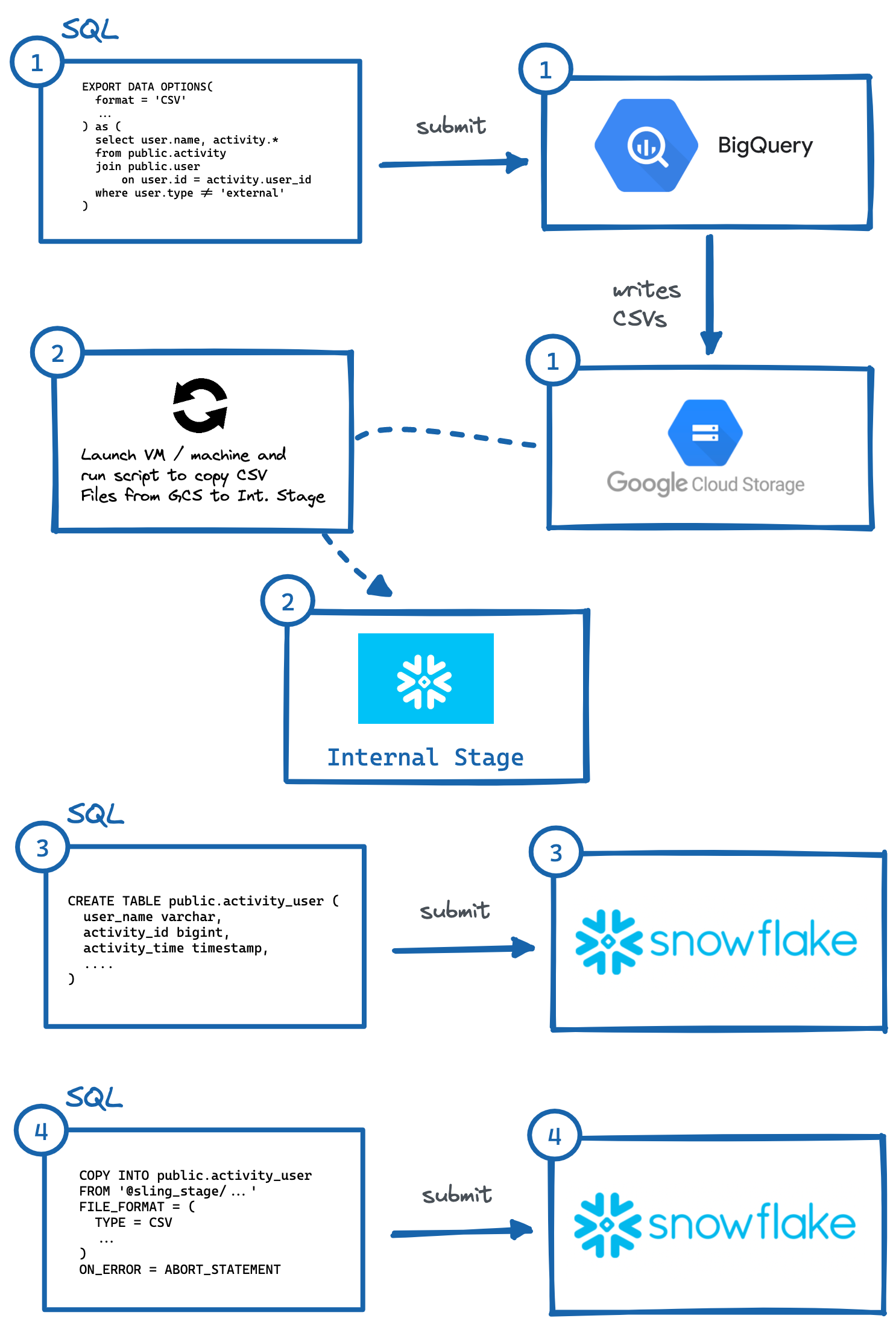 Изображение: шаги по ручному экспорту из BigQuery в Snowflake.
Изображение: шаги по ручному экспорту из BigQuery в Snowflake.Как было показано выше, для этого необходимо выполнить несколько шагов, при которых необходимо взаимодействовать с независимыми системами. Это может быть обременительно для автоматизации, особенно создание правильного DDL (#3) с правильными типами столбцов в целевой системе (что лично я считаю наиболее обременительным, попробуйте сделать это для таблиц с 50+ столбцами).
К счастью, есть более простой способ сделать это с помощью отличного инструмента под названием Sling. Sling — это инструмент интеграции данных, который позволяет легко и эффективно перемещать данные (извлечение и загрузка) из/в базы данных, платформы хранения и приложения SaaS. Есть два способа его использования: Sling CLI и Sling Cloud. Мы проделаем ту же процедуру, что и выше, но только предоставив входные данные для слинга, и он автоматически выполнит сложные шаги за нас!
Использование интерфейса командной строки Sling
Если вы фанатик командной строки, Sling CLI для вас. Он встроен в go (что делает его сверхбыстрым) и работает с файлами, базами данных и различными конечными точками SaaS. Он также может работать с Unix Pipes (читает стандартный ввод и записывает на стандартный вывод). Мы можем быстро установить его из нашей оболочки:
# На Mac
brew install slingdata-io/sling/sling
# В Windows Powershell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Использование Python Wrapper через pip
pip install sling
См. здесь другие варианты установки (включая Linux). Существует также библиотека Python wrapper, которая полезна, если вы предпочитаете взаимодействовать с Sling внутри Python.
После установки мы сможем запустить команду sling, которая должна дать нам следующий вывод:
sling - An Extract-Load tool | https://slingdata.io/ru
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Теперь есть много способов настроить задачи, но для нашей области в этой статье нам сначала нужно добавить учетные данные подключения для BigQuery и Snowflake. (разовая работа). Мы можем сделать это, открыв файл ~/.sling/env.yaml и добавив учетные данные, которые должны выглядеть так:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
Отлично, теперь давайте проверим наши соединения:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Замечательно, теперь, когда мы настроили соединения, мы можем запустить нашу задачу:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
Вау, это было легко! Слинг сделал все шаги, которые мы описали ранее, автоматически. Мы даже можем экспортировать данные Snowflake обратно в нашу оболочку sdtout (в формате CSV), указав только идентификатор таблицы (public.activity_user) для флага --src-stream и подсчитав строки для проверки наших данных:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Использование Sling Cloud
Теперь давайте проделаем то же самое с приложением Sling Cloud. Sling Cloud использует тот же движок, что и Sling CLI, за исключением того, что это полностью размещенная платформа для выполнения всех ваших потребностей в извлечении и загрузке по конкурентоспособной цене (ознакомьтесь с нашей [страницей с ценами] (https://slingdata.io/ru/ ценник)). С Sling Cloud мы можем:
Сотрудничайте со многими членами команды
Управление несколькими рабочими пространствами/проектами
Расписание задач извлечения-загрузки (EL) для запуска с интервалом или в фиксированное время (CRON) — Сбор и анализ журналов для отладки — Уведомления об ошибках по электронной почте или в Slack — Запуск из регионов по всему миру или в режиме собственного размещения, если это необходимо (где Sling Cloud является оркестратором).
Интуитивно понятный пользовательский интерфейс (UI) для быстрой настройки и выполнения
Первым делом зарегистрируйте бесплатную учетную запись здесь. После входа в систему мы можем выбрать режим
Cloud Mode(подробнее о режимеSelf-Hostedпозже). Теперь мы можем выполнить те же шаги, что и выше, но с помощью пользовательского интерфейса Sling Cloud:
Добавление соединения BigQuery
Шаги со скриншотами
Перейдите к Connections, нажмите New Connection, выберите Big Query.
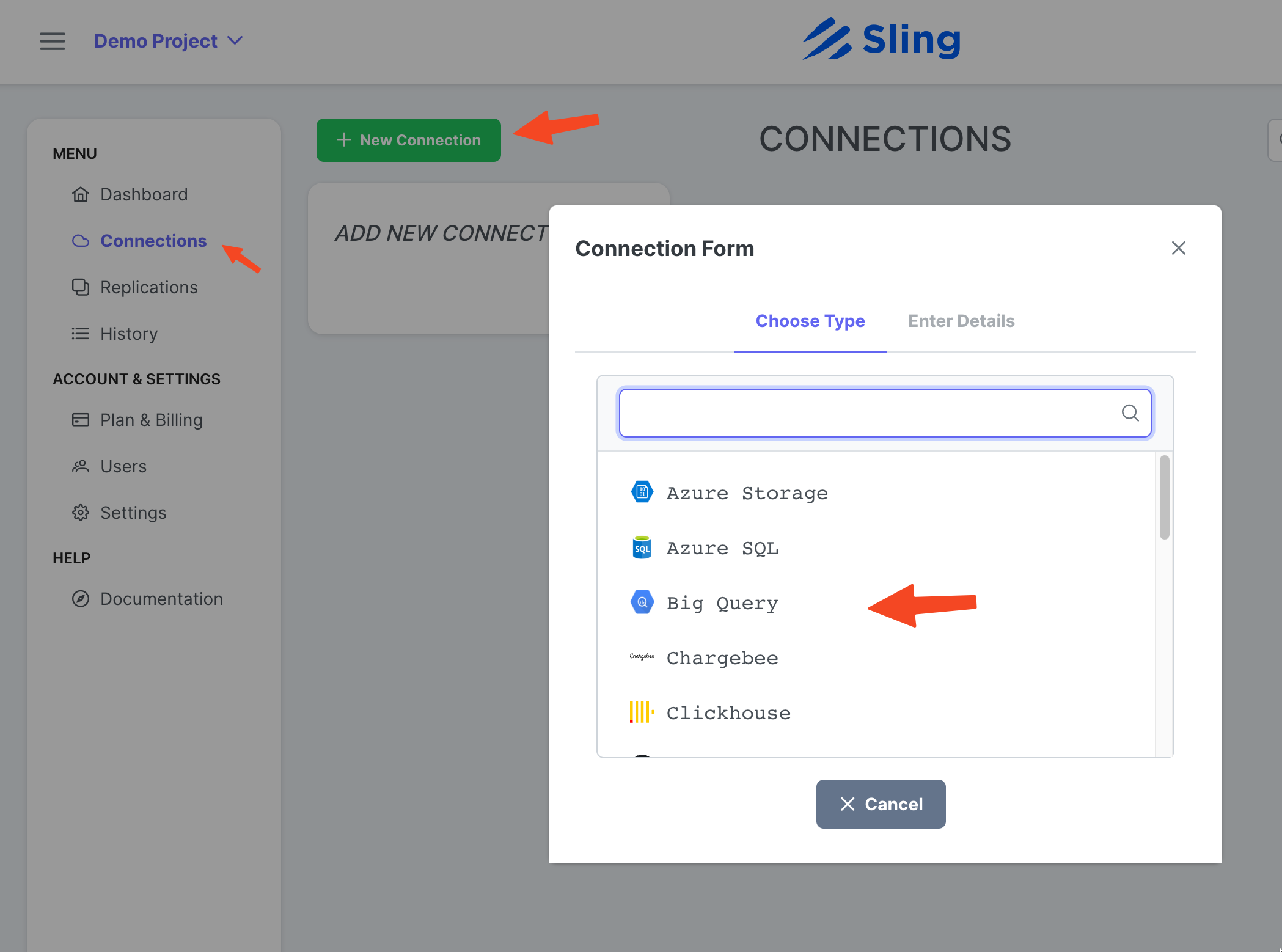
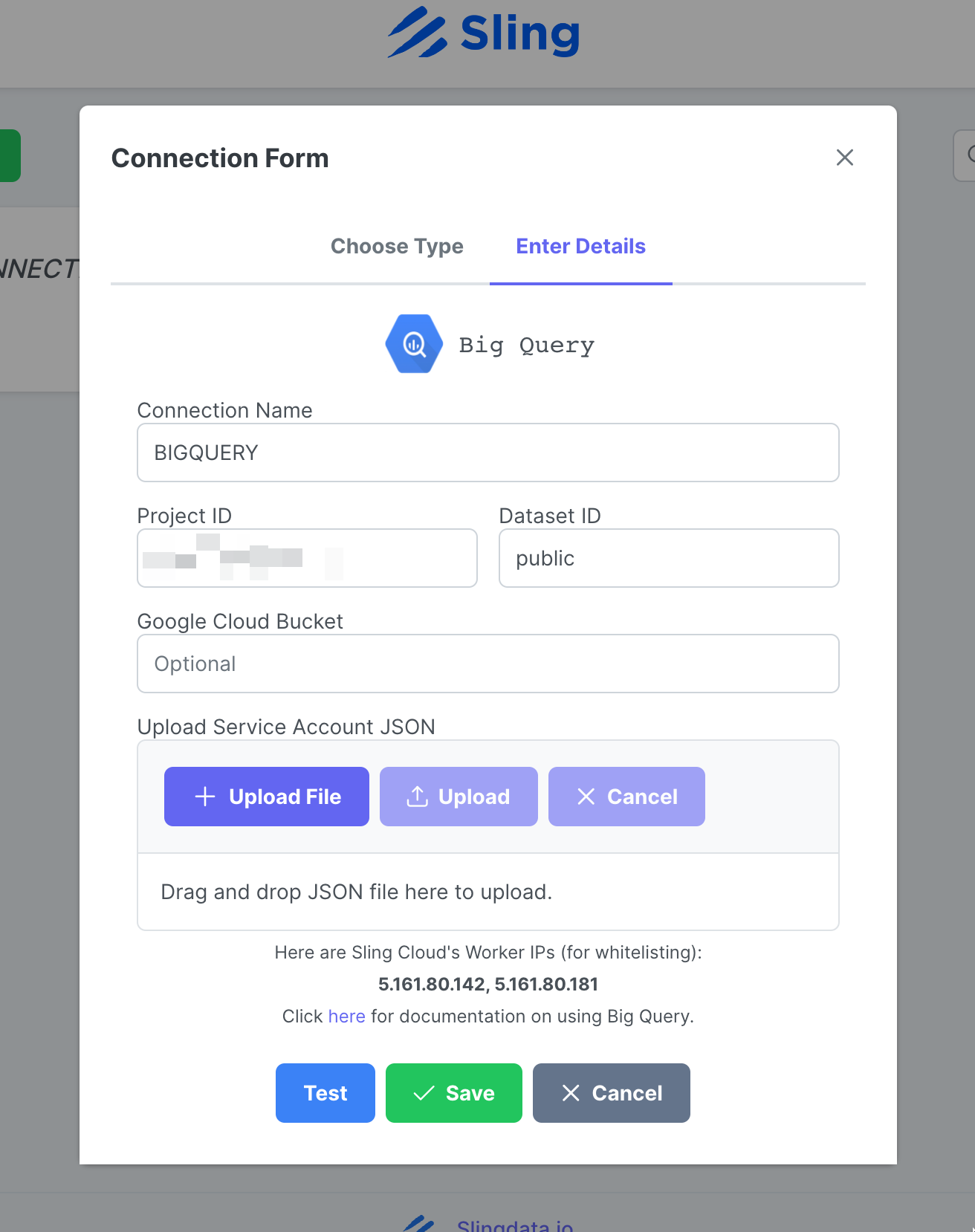
Введите имя BIGQUERY, свои учетные данные и загрузите JSON-файл своей учетной записи Google. Нажмите Test, чтобы проверить подключение, затем Save.
Добавление соединения "Снежинка"
Шаги со скриншотами
Нажмите New Connection, выберите Snowflake.
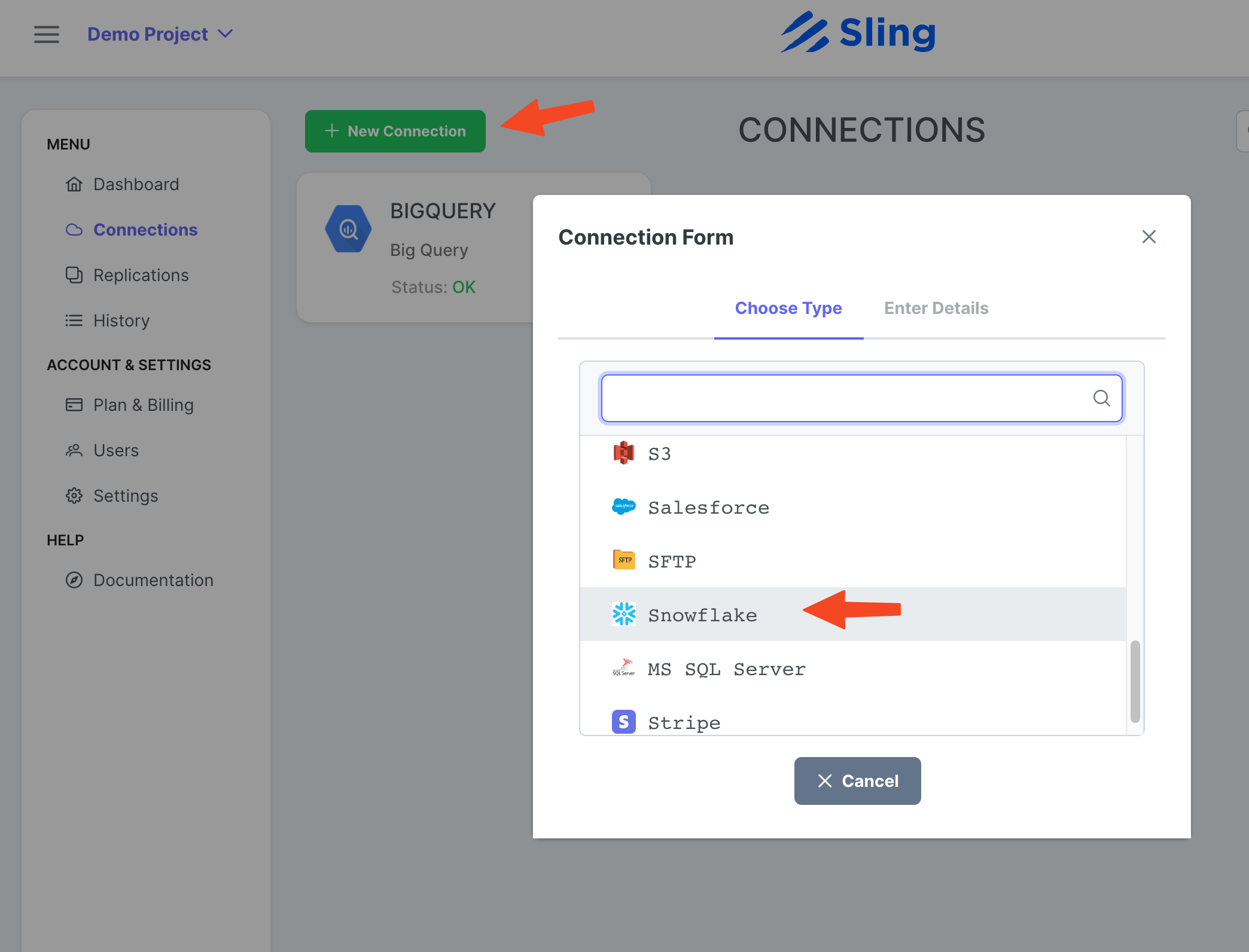
Введите имя SNOWFLAKE и свои учетные данные. Нажмите Test, чтобы проверить подключение, затем Save.
Создать репликацию
Шаги со скриншотами
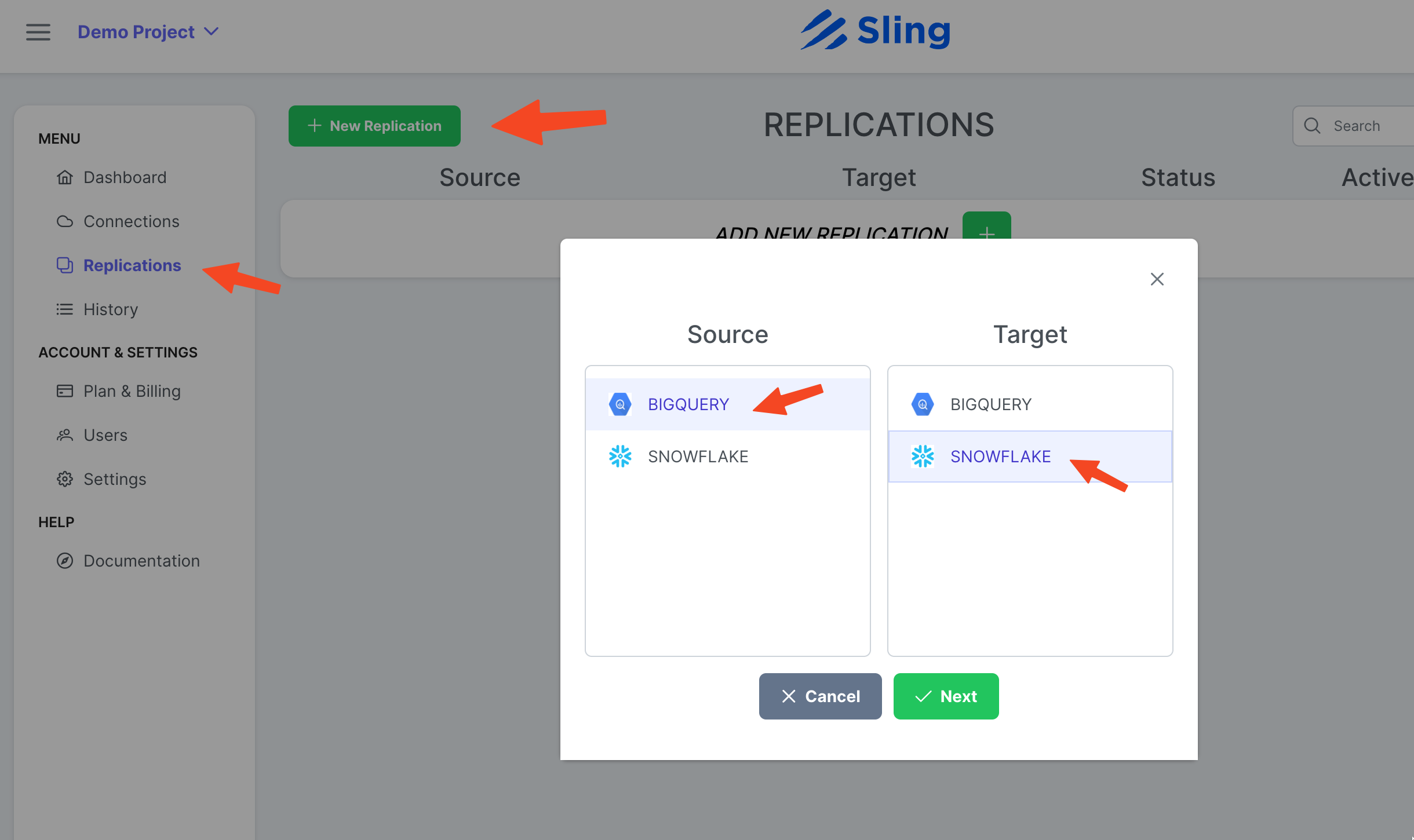
Перейдите к Replications, нажмите New Replication, выберите Big Query в качестве источника и Snowflake в качестве назначения. Нажмите Next.
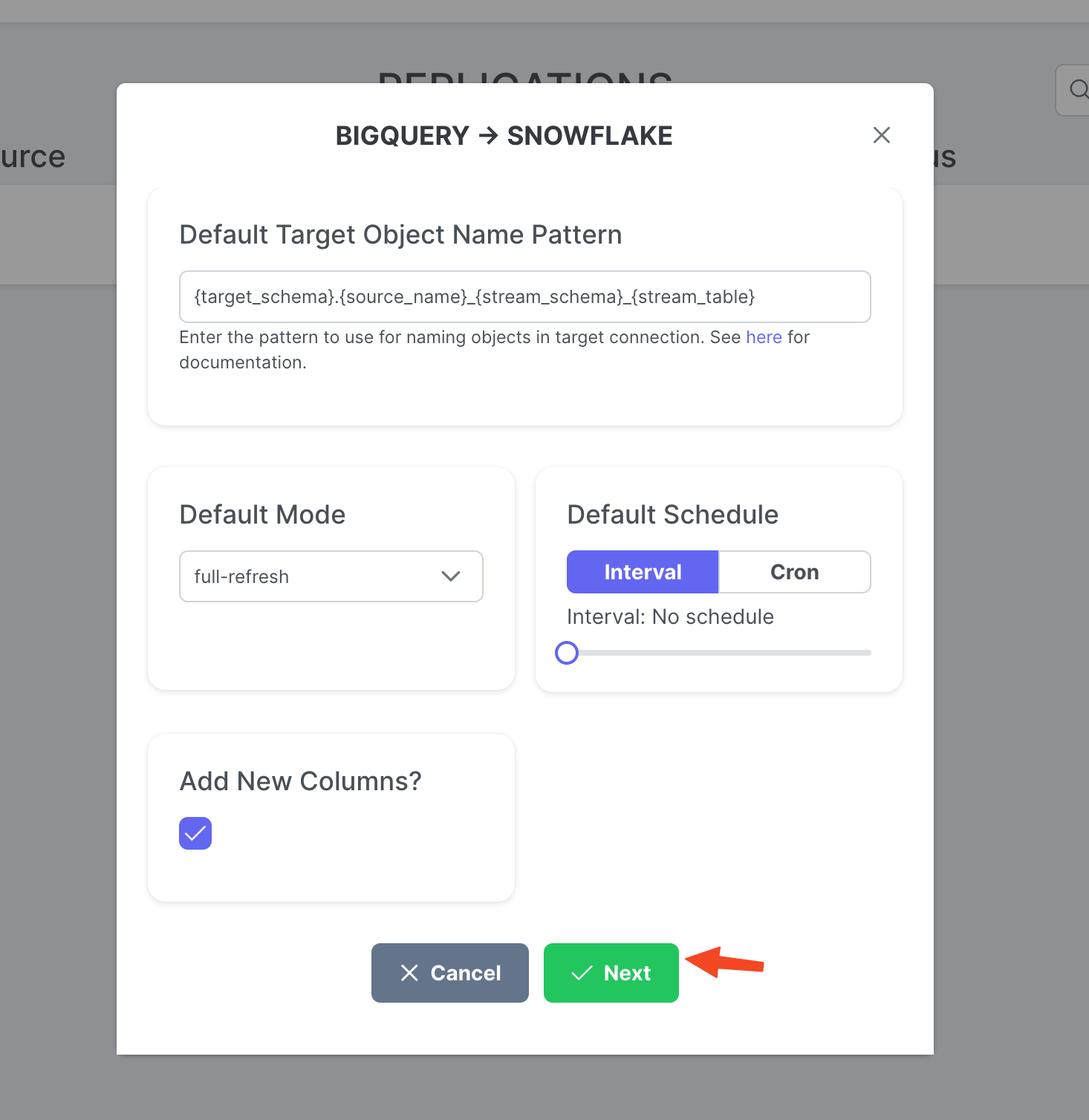
При необходимости установите Target Object Name Pattern и нажмите Create.
Создать и запустить задачу
Шаги со скриншотами
Перейдите на вкладку Streams, щелкните New SQL Stream, поскольку в качестве исходных данных используется пользовательский SQL. Дайте ему имя (activity_user). Вставьте запрос SQL, нажмите Ok.
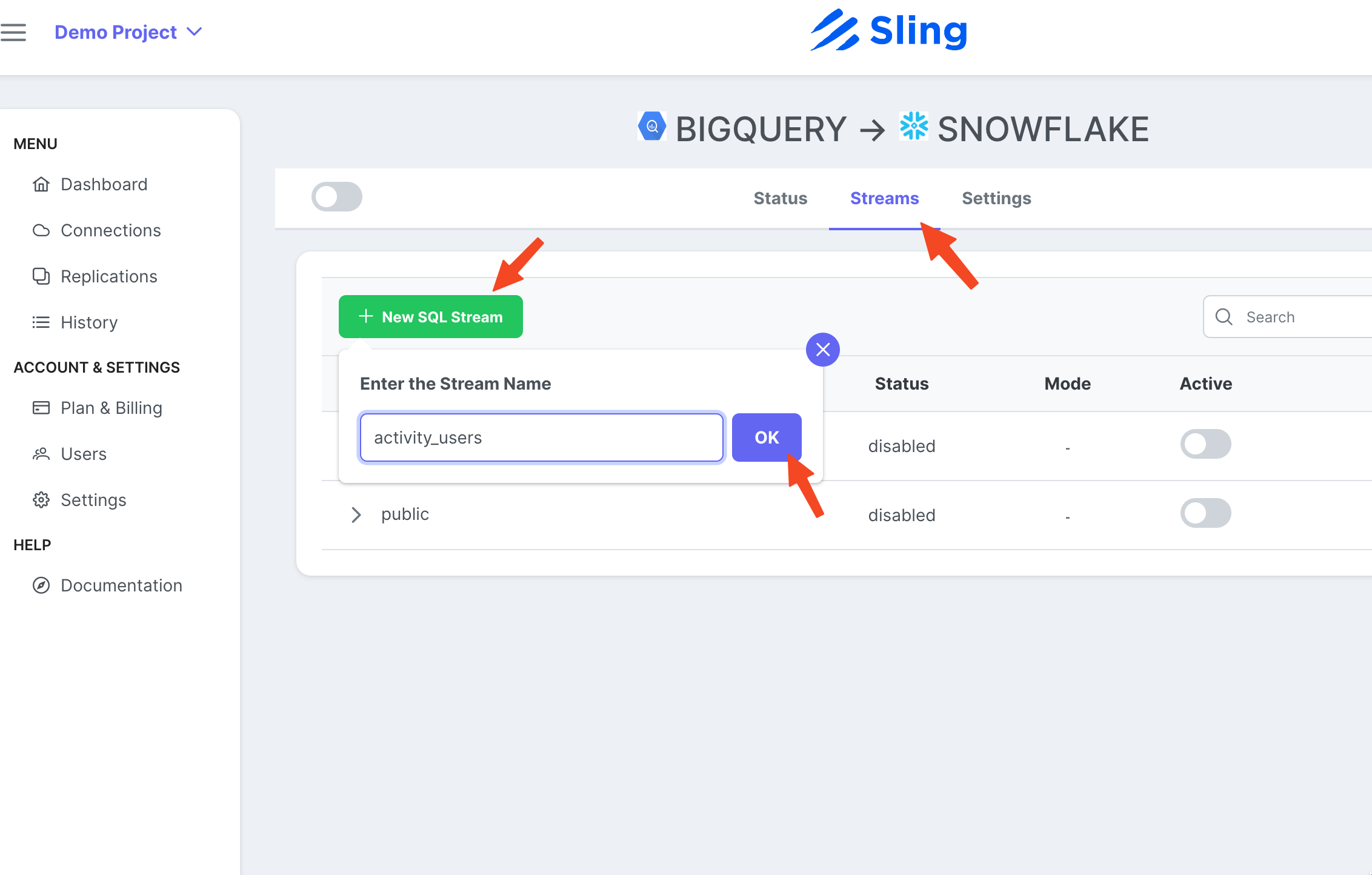
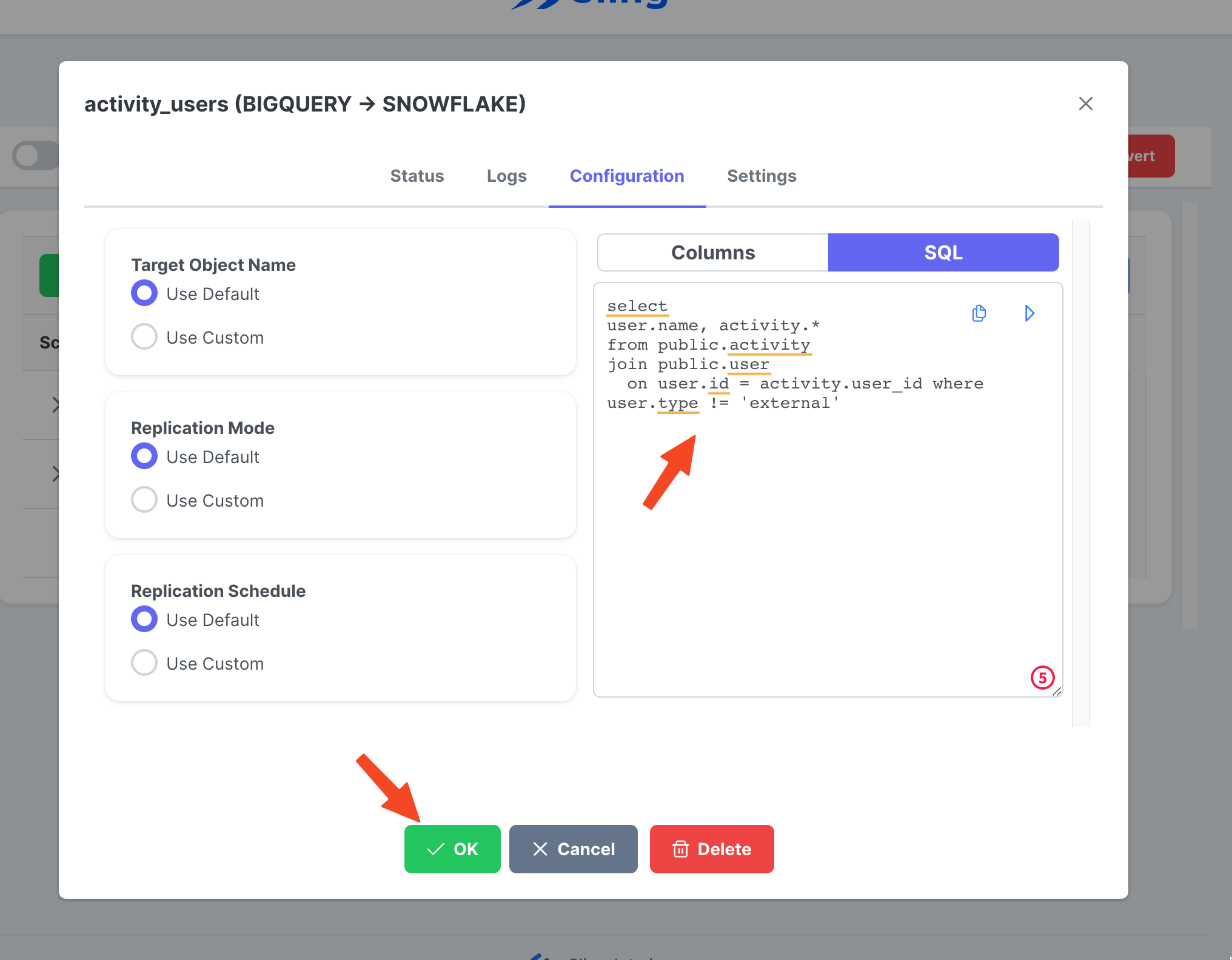
Теперь, когда у нас есть готовая потоковая задача, мы можем нажать значок воспроизведения, чтобы запустить ее.
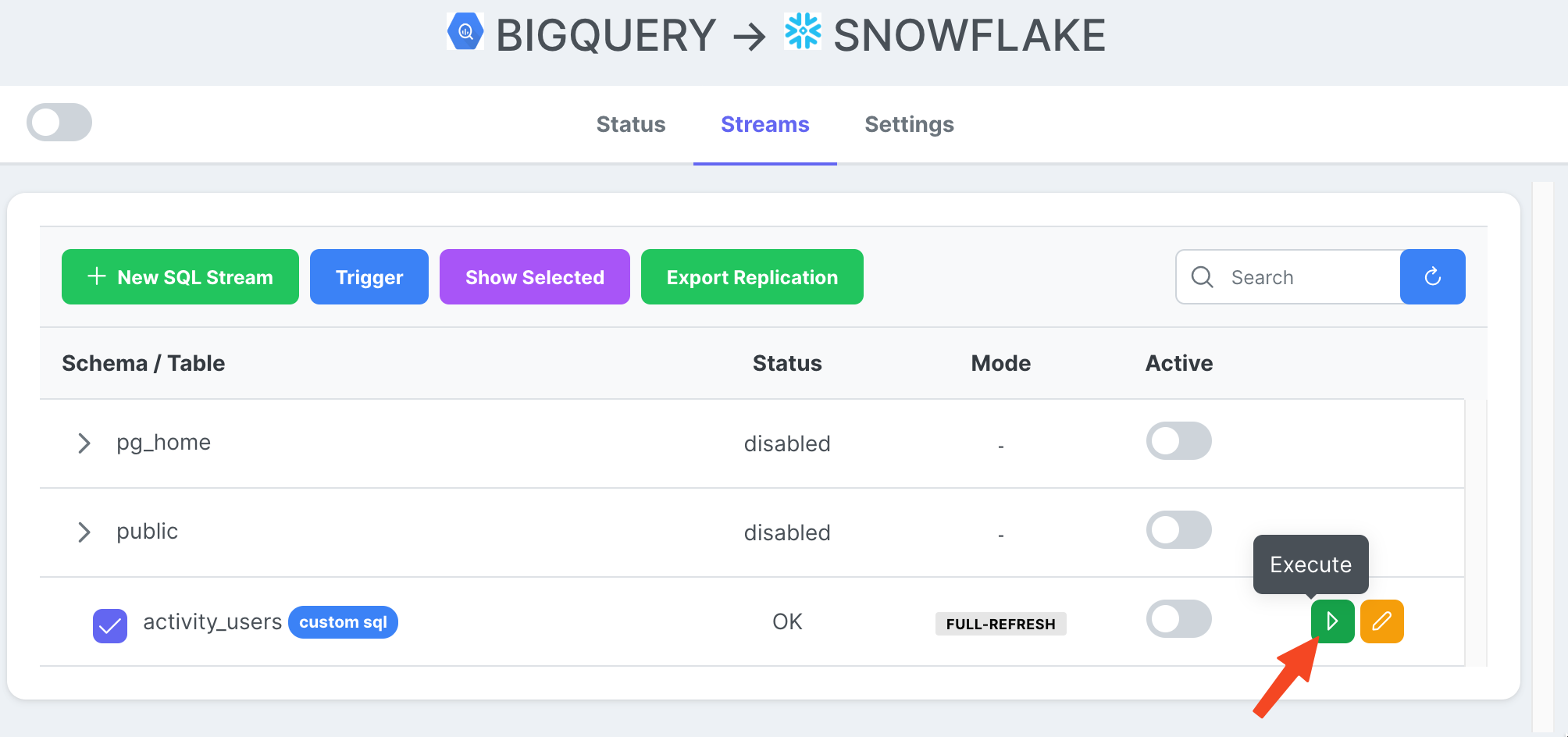
После завершения выполнения задачи мы можем просмотреть журналы.
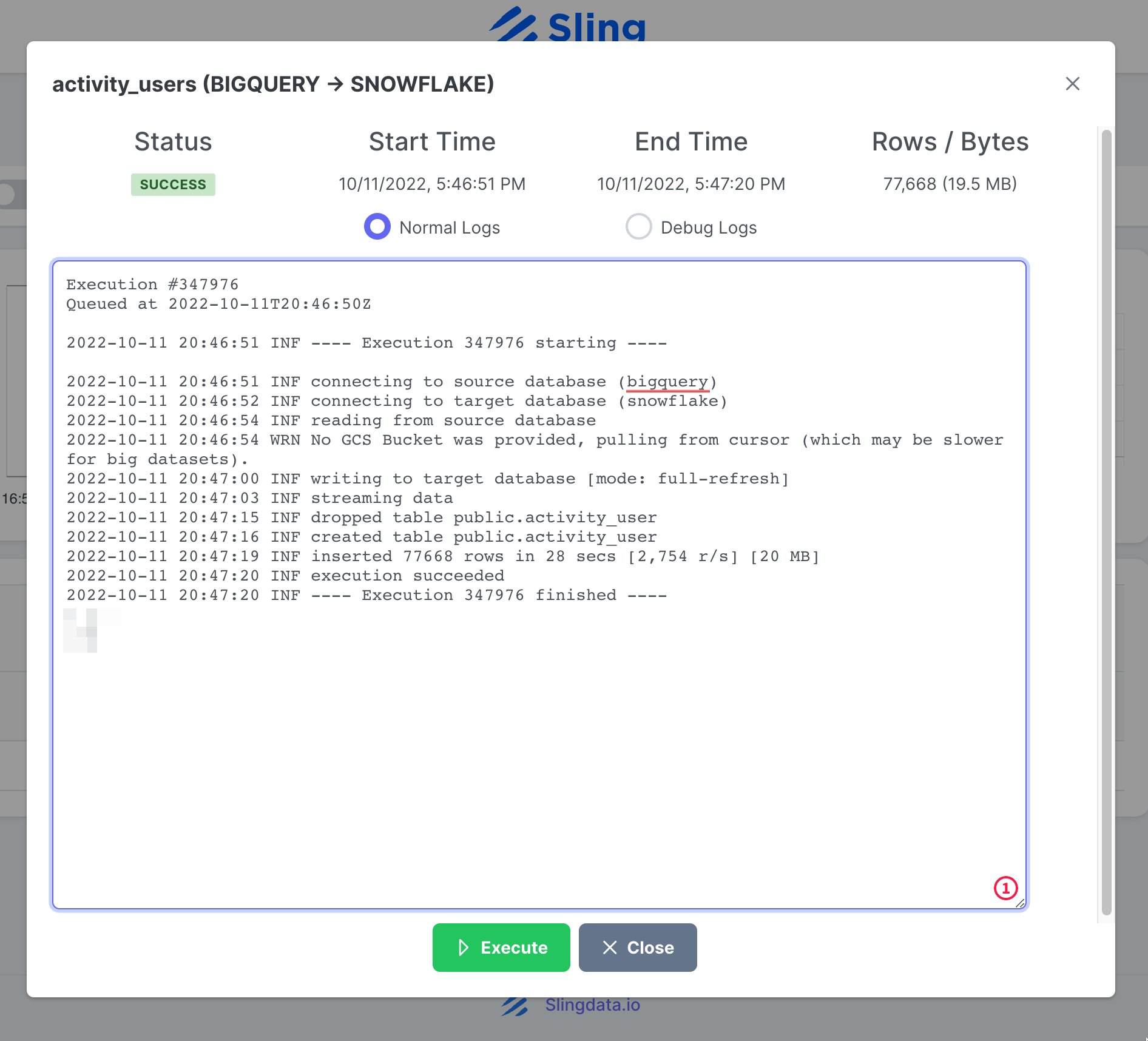
Всё! У нас есть настройка задачи, и мы можем повторно запустить ее по требованию или установить ее по расписанию. Как вы могли заметить, Sling Cloud обрабатывает для нас еще несколько вещей и предоставляет пользователям, ориентированным на пользовательский интерфейс, лучший опыт по сравнению с Sling CLI.
Заключение
Мы живем в эпоху, когда данные — это золото, и перенос данных с одной платформы на другую не должен вызывать затруднений. Как мы уже продемонстрировали, Sling предлагает мощную альтернативу за счет уменьшения трения, связанного с интеграцией данных. Мы расскажем, как экспортировать данные из Snowflake и загрузить их в BigQuery, в другом посте.

