
Entrepôts de données cloud
Au cours des dernières années, nous avons constaté une croissance rapide de l'utilisation des entrepôts de données dans le cloud (ainsi que du paradigme "warehouse-first"). Deux plates-formes DWH cloud populaires sont BigQuery et Snowflake. Consultez le tableau ci-dessous pour voir leur évolution dans le temps.
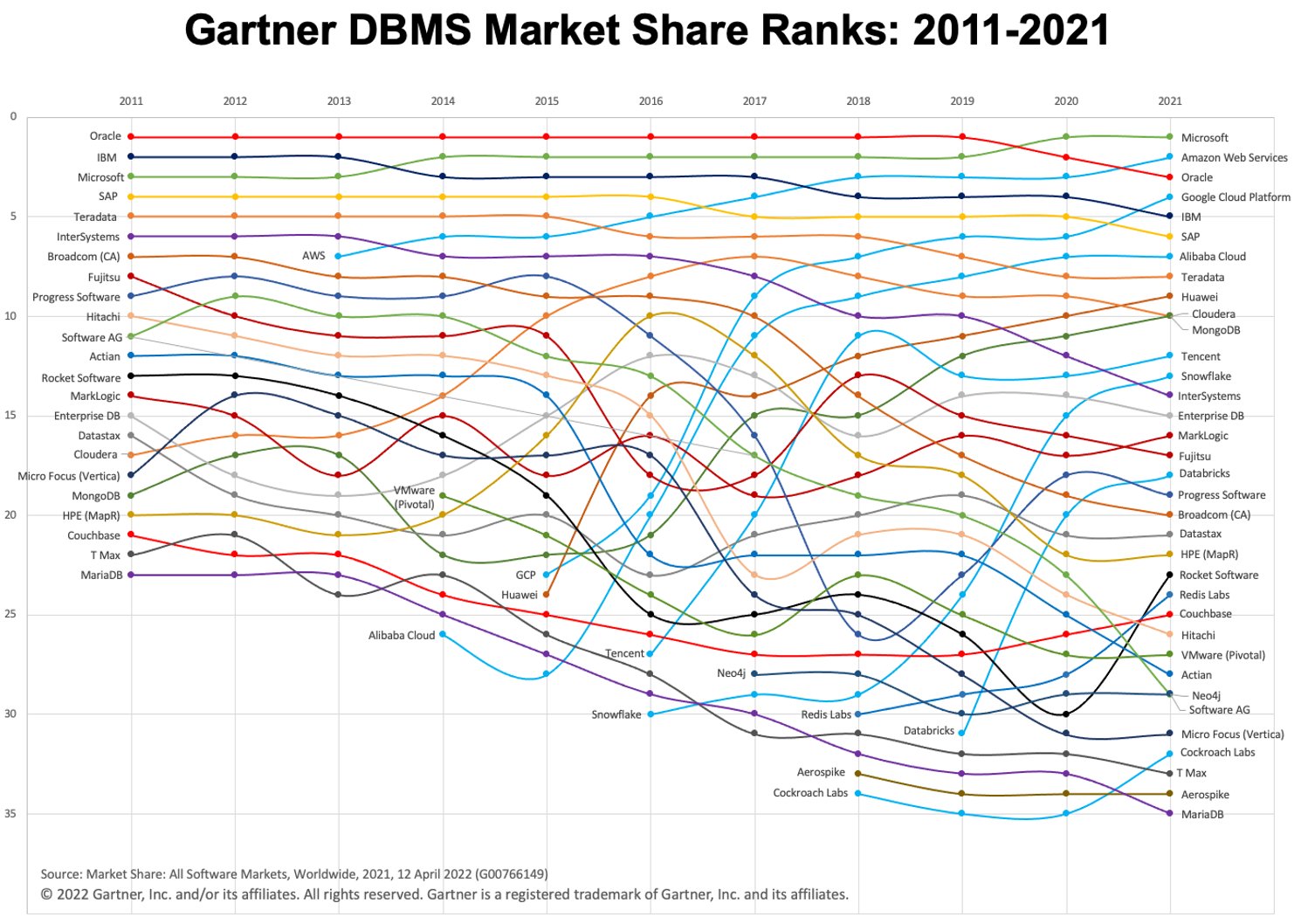 Image : Gartner via Adam Ronthal (@aronthal) sur Twitter.
Image : Gartner via Adam Ronthal (@aronthal) sur Twitter.
BigQuery, au 4e rang en 2021, est un service d'entrepôt de données sans serveur entièrement géré proposé par Google Cloud Platform (GCP). Il permet une analyse facile et évolutive sur des pétaoctets de données et est connu depuis longtemps pour sa facilité d'utilisation et sa nature sans maintenance.
Snowflake, est un service similaire proposé par la société Snowflake Inc. L'une des principales différences est que Snowflake vous permet d'héberger l'instance dans Amazon Web Services (AWS), Azure (Microsoft) ou GCP (Google). C'est un grand avantage si vous êtes déjà établi dans un environnement non-GCP.
Exportation et chargement des données
Selon les circonstances, il est parfois nécessaire ou souhaité de copier des données d'un environnement BigQuery vers un environnement Snowflake. Jetons un coup d'œil et décomposons les différentes étapes logiques nécessaires pour déplacer correctement ces données, car aucun des services concurrents n'a de fonction intégrée pour le faire facilement. Pour les besoins de notre exemple, nous supposerons que notre environnement Snowflake de destination est hébergé sur AWS.
Procédure étape par étape
Afin de migrer des données de BigQuery vers Snowflake (AWS), voici les étapes essentielles :
Identifiez la table ou la requête et exécutez la requête
EXPORT DATA OPTIONSpour exporter vers Google Cloud Storage (GCS).Exécutez le script sur une machine virtuelle ou une machine locale pour copier les données GCS sur la scène interne de Snowflake. Nous pourrions également lire directement à partir de GCS avec une intégration de stockage, mais cela implique une autre couche de configuration d'accès sécurisé (ce qui peut être préférable pour votre cas d'utilisation).
Générez manuellement le DDL
CREATE TABLEavec les types de données de colonne corrects et exécutez-le dans Snowflake.Exécutez une requête
COPYdans Snowflake pour importer des fichiers préparés.Éventuellement, nettoyez (supprimez) les données temporaires dans GCP et l'étape interne.
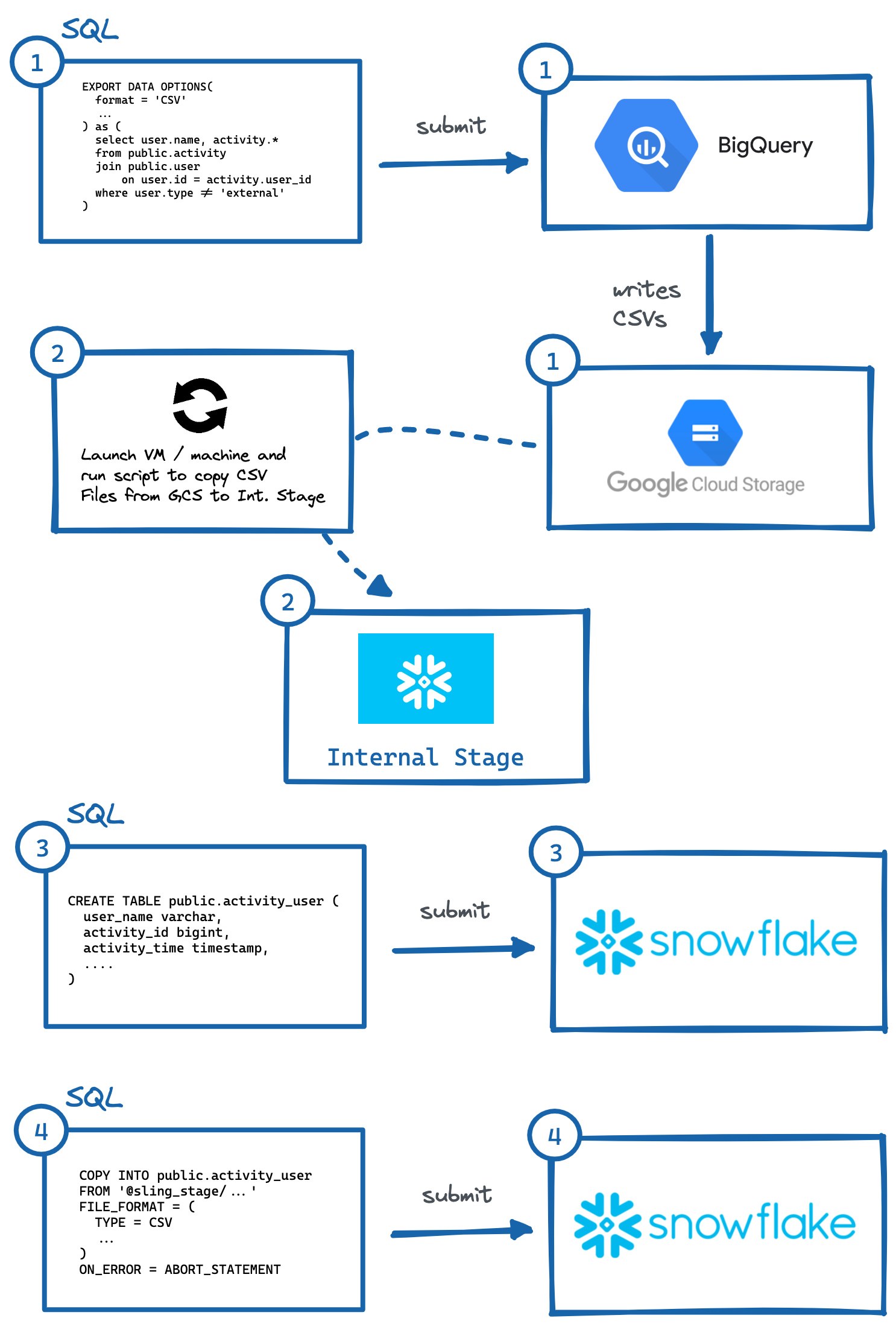 Image : Étapes pour exporter manuellement de BigQuery vers Snowflake.
Image : Étapes pour exporter manuellement de BigQuery vers Snowflake.Comme démontré ci-dessus, il y a plusieurs étapes pour y parvenir, où des systèmes indépendants doivent interagir avec. Cela peut être fastidieux à automatiser, en particulier générer le DDL correct (#3) avec les types de colonnes appropriés dans le système de destination (ce que je trouve personnellement le plus lourd, essayez de le faire pour les tables avec plus de 50 colonnes).
Heureusement, il existe un moyen plus simple de le faire, et c'est en utilisant un outil astucieux appelé Sling. Sling est un outil d'intégration de données qui permet un déplacement simple et efficace des données (extraction et chargement) depuis/vers les bases de données, les plates-formes de stockage et les applications SaaS. Il existe deux façons de l'utiliser : Sling CLI et Sling Cloud. Nous ferons la même procédure que ci-dessus, mais uniquement en fournissant des entrées à sling et il effectuera automatiquement les étapes complexes pour nous !
Utilisation de Sling CLI
Si vous êtes un fanatique de la ligne de commande, Sling CLI est fait pour vous. Il est intégré à go (ce qui le rend ultra-rapide) et fonctionne avec des fichiers, des bases de données et divers points de terminaison saas. Il peut également fonctionner avec Unix Pipes (lit l'entrée standard et écrit sur la sortie standard). On peut l'installer rapidement depuis notre shell :
# Sur Mac
brew install slingdata-io/sling/sling
# Sous Windows Powershell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Utilisation de Python Wrapper via pip
pip install sling
Veuillez consulter ici pour d'autres options d'installation (y compris Linux). Il existe également une bibliothèque Python wrapper, qui est utile si vous préférez interagir avec Sling dans Python.
Une fois installé, nous devrions être en mesure d'exécuter la commande sling, qui devrait nous donner cette sortie :
sling - An Extract-Load tool | https://slingdata.io/fr
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Maintenant, il existe de nombreuses façons de [configurer des tâches] (https://docs.slingdata.io/sling-cli/configuration), mais pour notre portée dans cet article, nous devons d'abord ajouter des informations d'identification de connexion pour BigQuery et Snowflake (une corvée unique). Nous pouvons le faire en ouvrant le fichier ~/.sling/env.yaml et en ajoutant les informations d'identification, qui devraient ressembler à ceci :
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
Super, testons maintenant nos connexions :
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Fantastique, maintenant que nous avons configuré nos connexions, nous pouvons exécuter notre tâche :
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
Wow, c'était facile ! Sling a effectué automatiquement toutes les étapes que nous avons décrites précédemment. Nous pouvons même exporter les données Snowflake vers notre shell sdtout (au format CSV) en fournissant uniquement l'identifiant de table (public.activity_user) pour le drapeau --src-stream et compter les lignes pour valider nos données :
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Utiliser Sling Cloud
Faisons maintenant la même chose avec l'application Sling Cloud. Sling Cloud utilise le même moteur que Sling CLI, sauf qu'il s'agit d'une plate-forme entièrement hébergée pour exécuter tous vos besoins Extract-Load à un prix compétitif (consultez notre [page de tarification](https://slingdata.io/fr/ prix)). Avec Sling Cloud, nous pouvons :
Collaborer avec de nombreux membres de l'équipe
Gérer plusieurs espaces de travail/projets
Planifier des tâches d'extraction-chargement (EL) à exécuter à un intervalle ou à des heures fixes (CRON)
Collecter et analyser les journaux pour le débogage
Notifications d'erreur par e-mail ou Slack
Exécuter à partir de régions du monde entier ou en mode auto-hébergé si vous le souhaitez (où Sling Cloud est l'orchestrateur).
Interface utilisateur (UI) intuitive pour une configuration et une exécution rapides
La première chose à faire est de créer un compte gratuit ici. Une fois connecté, nous pouvons sélectionner le
Cloud Mode(plus sur le modeSelf-Hostedplus tard). Nous pouvons maintenant effectuer des étapes similaires à celles ci-dessus, mais en utilisant l'interface utilisateur Sling Cloud :
Ajout de la connexion BigQuery
Étapes avec captures d'écran
Allez sur Connections, cliquez sur New Connection, sélectionnez Big Query.
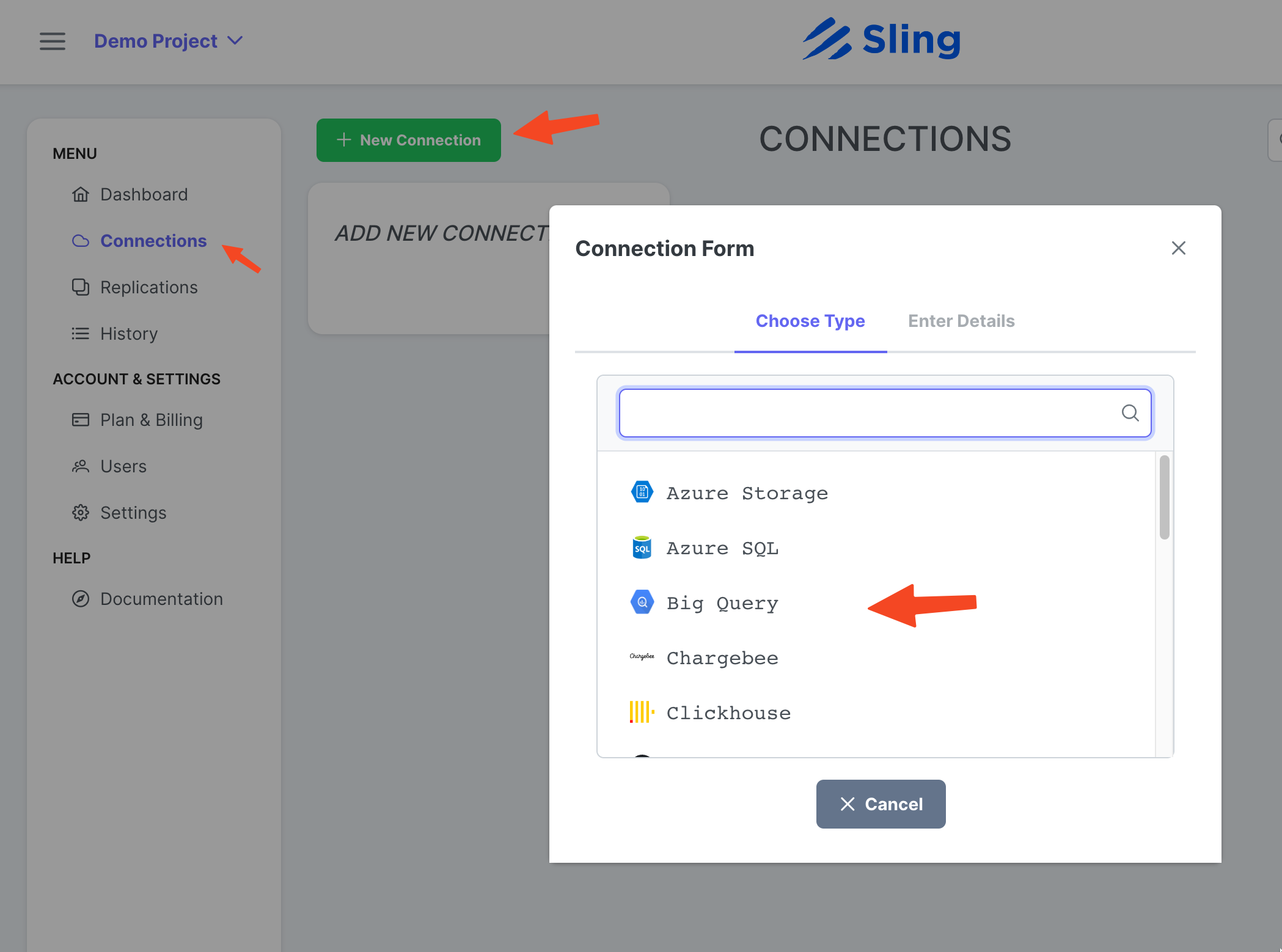
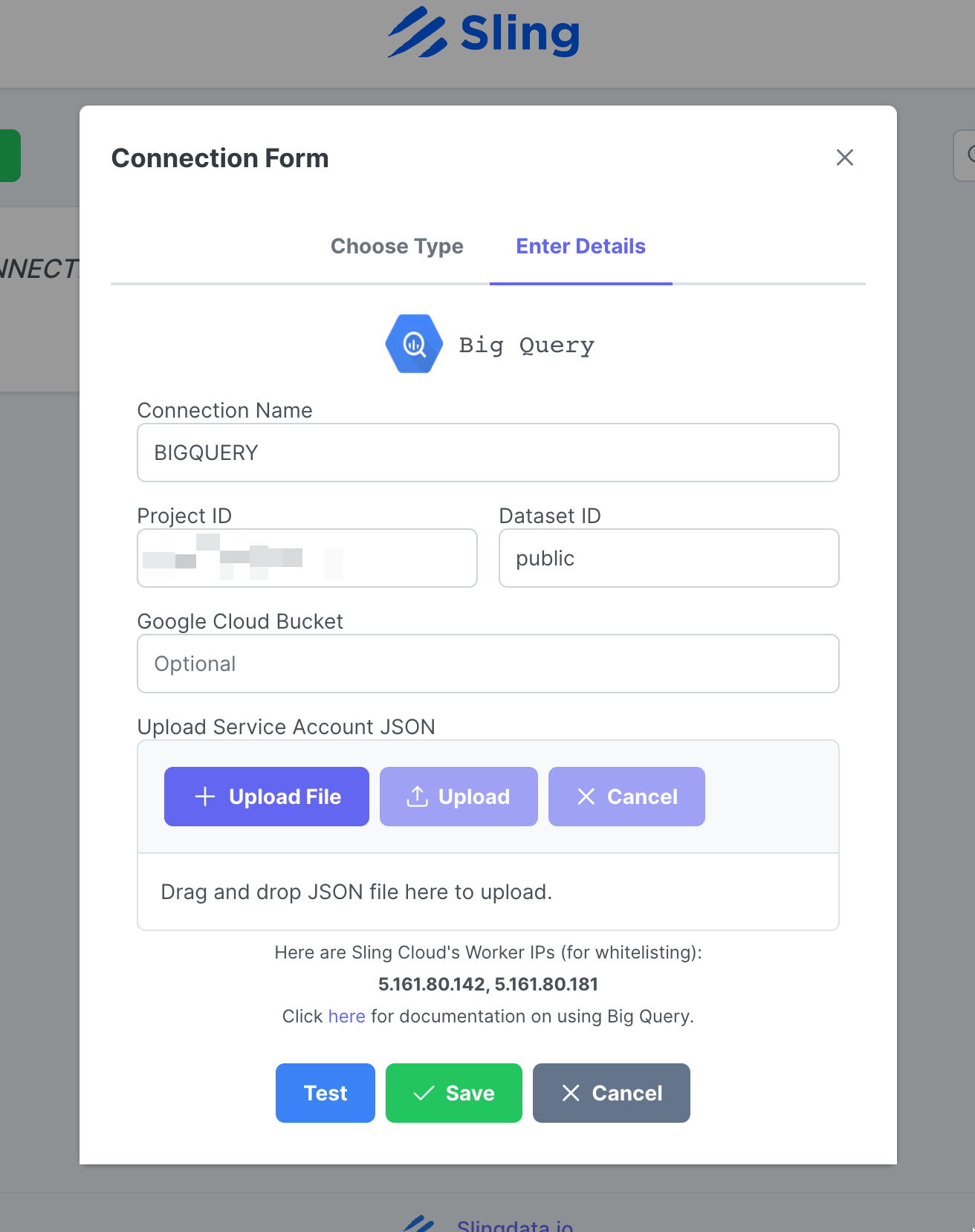
Entrez le nom BIGQUERY, vos informations d'identification et téléchargez le fichier JSON de votre compte Google. Cliquez sur Test pour tester la connectivité, puis sur Save.
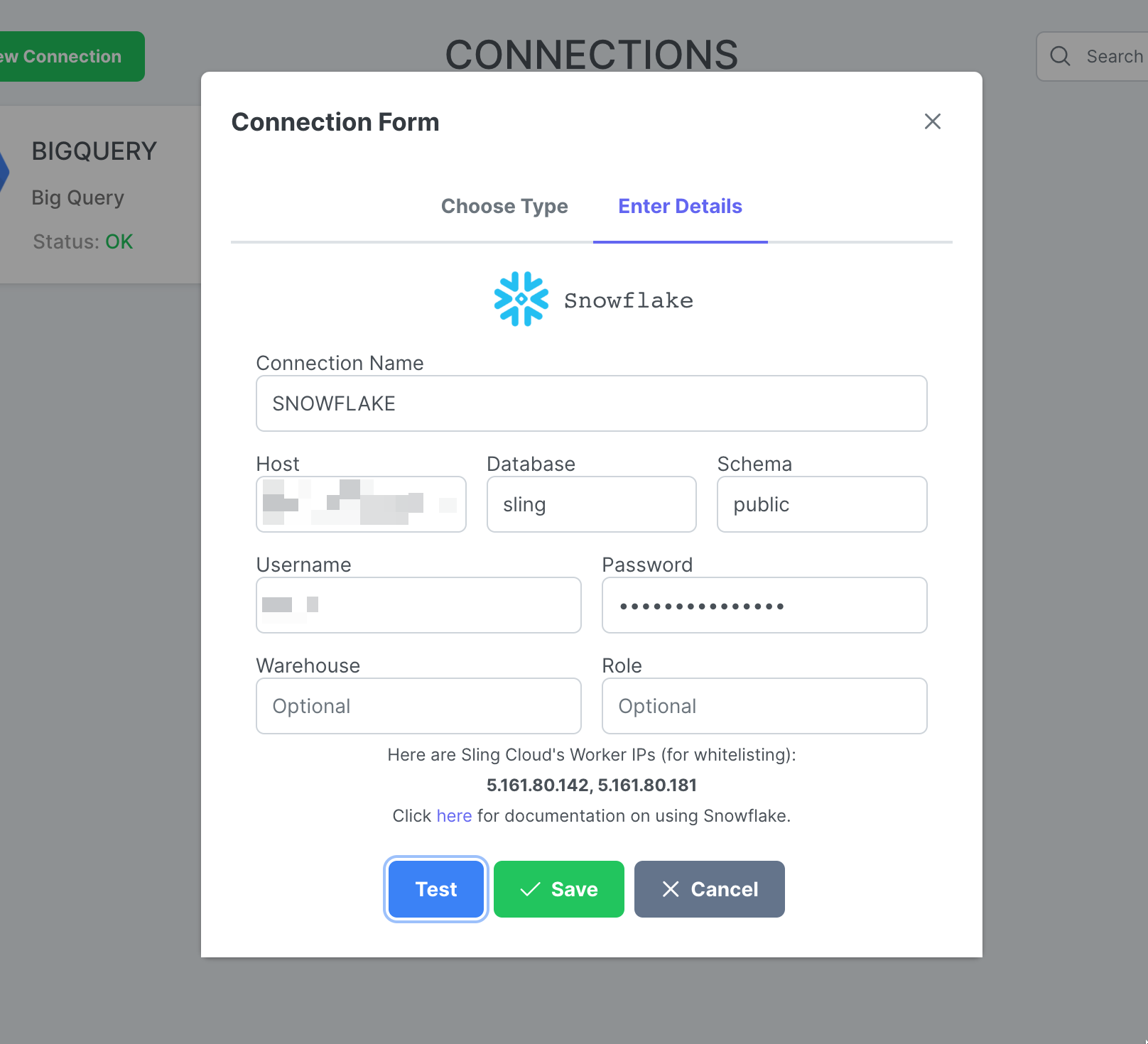
Ajout de la connexion flocon de neige
Étapes avec captures d'écran
Cliquez sur New Connection, sélectionnez Snowflake.

Entrez le nom SNOWFLAKE et vos informations d'identification. Cliquez sur Test pour tester la connectivité, puis sur Save.
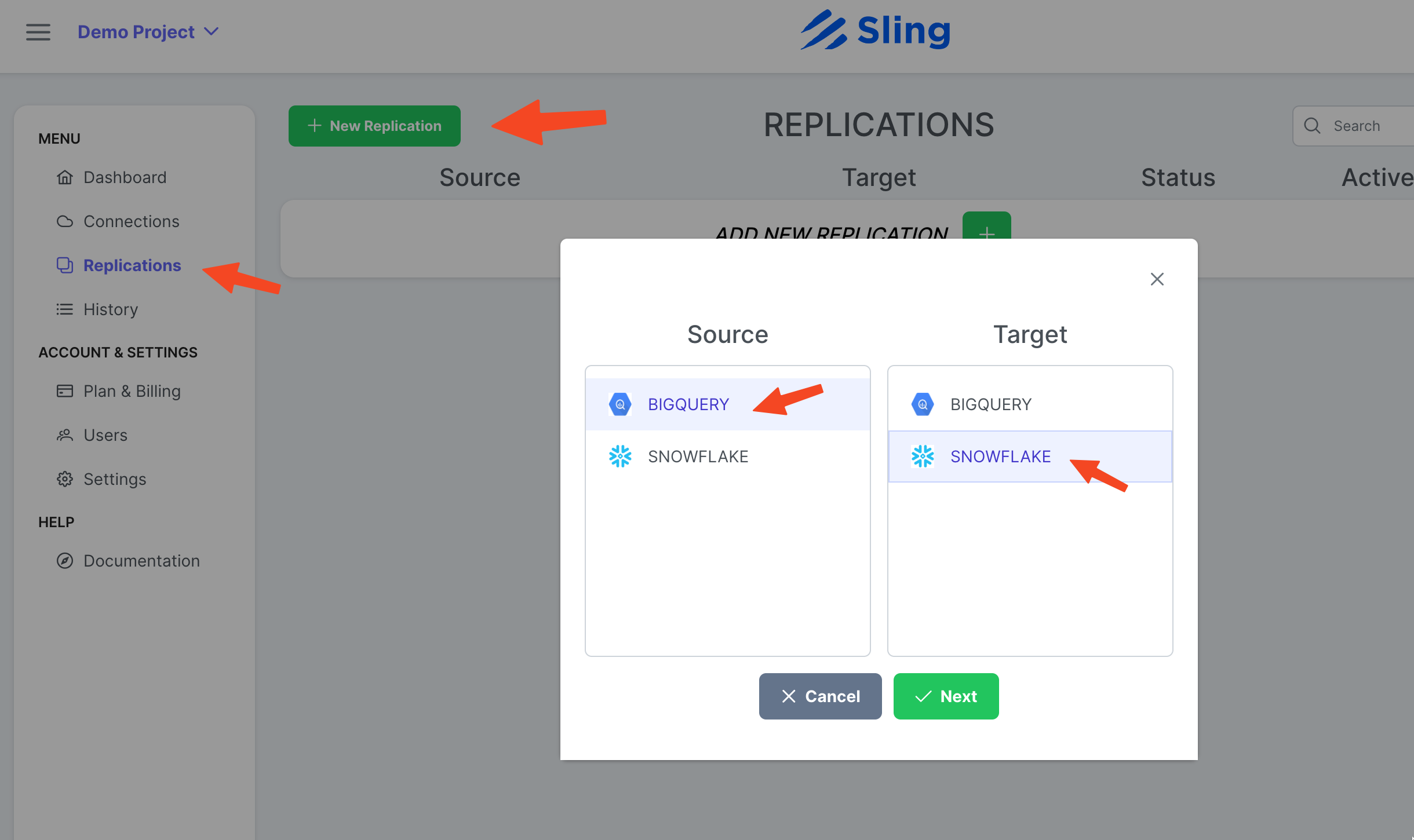
Créer une réplication
Étapes avec captures d'écran
Allez sur Replications, cliquez sur New Replication, sélectionnez Big Query comme source et Snowflake comme destination. Cliquez sur Next.
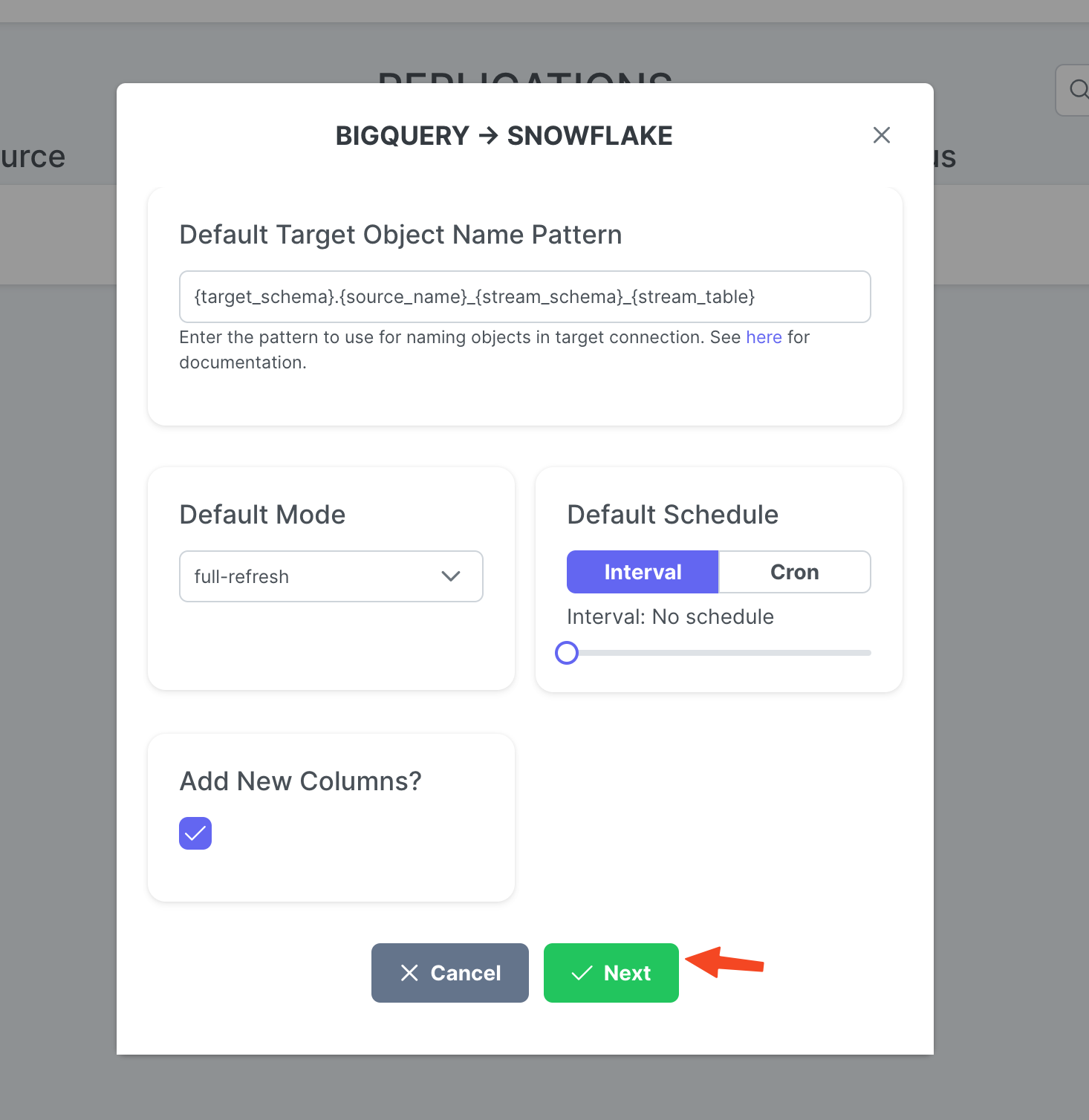
Réglez sur Target Object Name Pattern si vous le souhaitez et cliquez sur Create.
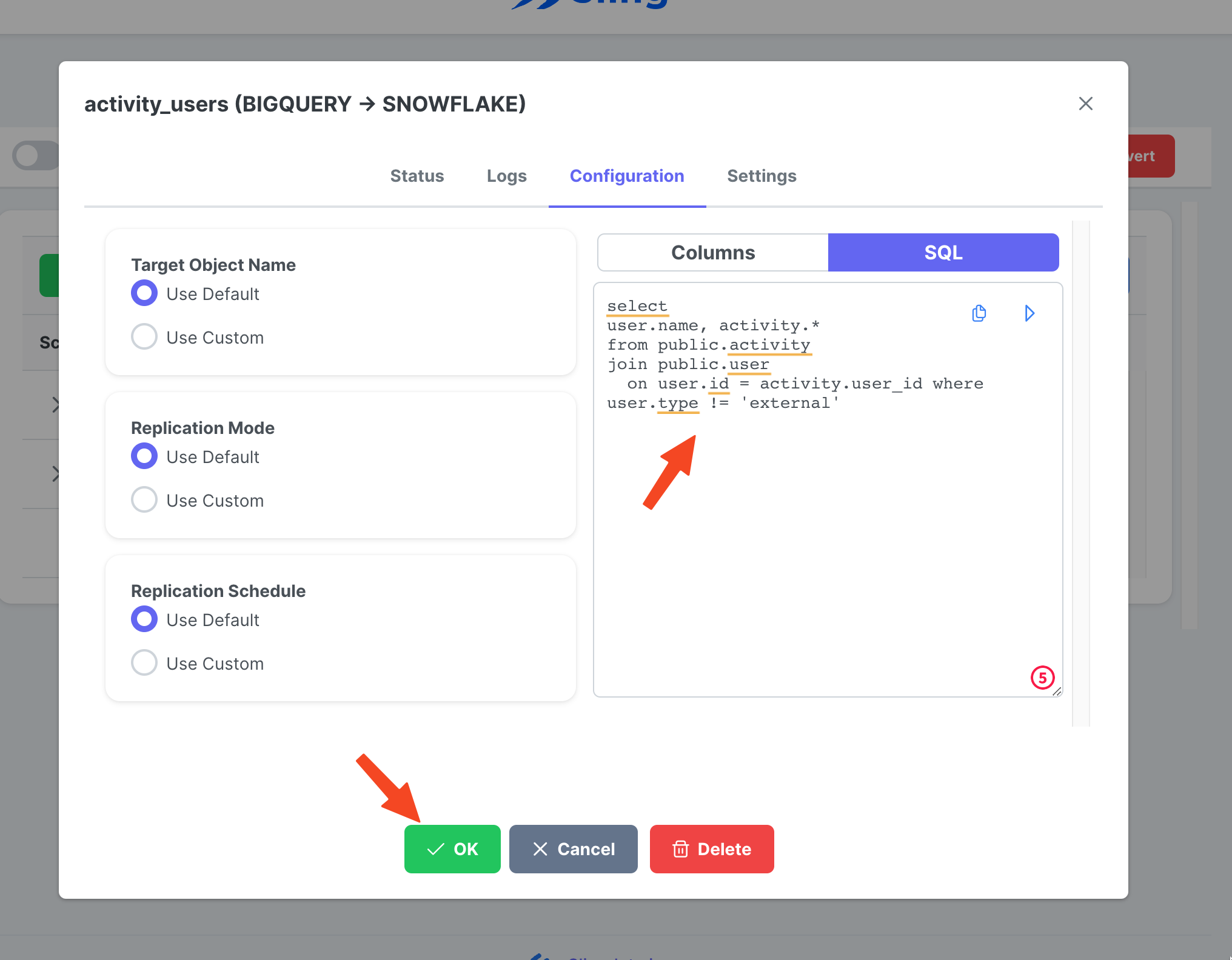
Créer et exécuter une tâche
Étapes avec captures d'écran
Allez dans l'onglet Streams, cliquez sur New SQL Stream puisque nous utilisons un SQL personnalisé comme source de données. Donne lui un nom (activity_user). Collez la requête SQL, cliquez sur Ok.

Maintenant que nous avons une tâche de flux prête, nous pouvons appuyer sur l'icône de lecture pour la déclencher.
Une fois l'exécution de la tâche terminée, nous pouvons inspecter les journaux.

C'est tout ! Nous avons configuré notre tâche et nous pouvons la réexécuter à la demande ou la définir selon un calendrier. Comme vous le remarquerez peut-être, Sling Cloud gère un peu plus de choses pour nous et offre aux utilisateurs orientés UI une meilleure expérience par rapport à Sling CLI.
Conclusion
Nous sommes à une époque où les données sont d'or, et déplacer des données d'une plate-forme à une autre ne devrait pas être difficile. Comme nous l'avons démontré, Sling offre une alternative puissante en réduisant les frictions associées à l'intégration des données. Nous verrons comment exporter depuis Snowflake et charger dans BigQuery dans un autre article.