
Cloud Data Warehouses
In den letzten Jahren haben wir ein schnelles Wachstum bei der Nutzung von Cloud Data Warehouses (sowie des „Warehouse-First“-Paradigmas) erlebt. Zwei beliebte Cloud-DWH-Plattformen sind BigQuery und Snowflake. Schauen Sie sich das Diagramm unten an, um ihre Entwicklung im Laufe der Zeit zu sehen.
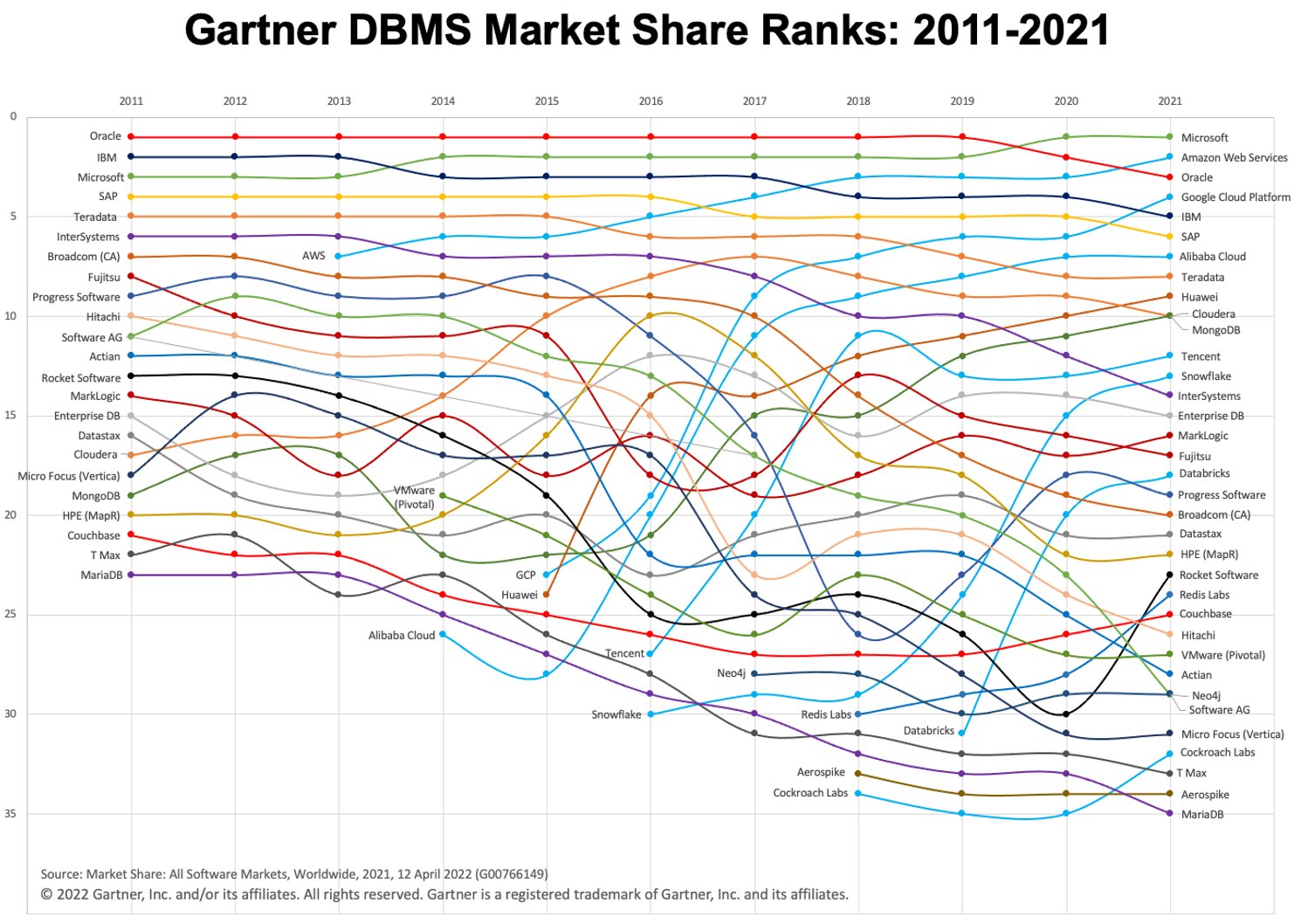 Bild: Gartner über Adam Ronthal (@aronthal) auf Twitter.
Bild: Gartner über Adam Ronthal (@aronthal) auf Twitter.
BigQuery, ab 2021 auf Platz 4, ist ein vollständig verwalteter, serverloser Data-Warehouse-Dienst, der von der Google Cloud Platform (GCP) angeboten wird. Es ermöglicht eine einfache und skalierbare Analyse von Petabytes an Daten und ist seit langem für seine Benutzerfreundlichkeit und Wartungsfreiheit bekannt.
Snowflake ist ein ähnlicher Dienst, der von der Firma Snowflake Inc. angeboten wird. Einer der Hauptunterschiede besteht darin, dass Sie mit Snowflake die Instanz entweder in Amazon Web Services (AWS), Azure (Microsoft) oder GCP (Google) hosten können. Dies ist ein großer Vorteil, wenn Sie bereits in einer Nicht-GCP-Umgebung etabliert sind.
Exportieren und Laden der Daten
Unter Umständen ist es manchmal notwendig oder erwünscht, Daten aus einer BigQuery-Umgebung in eine Snowflake-Umgebung zu kopieren. Lassen Sie uns einen Blick darauf werfen und die verschiedenen logischen Schritte aufschlüsseln, die erforderlich sind, um diese Daten richtig zu verschieben, da keiner der konkurrierenden Dienste eine integrierte Funktion hat, um dies einfach zu tun. Für unser Beispiel gehen wir davon aus, dass unsere Snowflake-Zielumgebung auf AWS gehostet wird.
Schrittweises Vorgehen
Um Daten von BigQuery zu Snowflake (AWS) zu migrieren, sind dies die wesentlichen Schritte:
Identifizieren Sie die Tabelle oder Abfrage und führen Sie
EXPORT DATA OPTIONSquery zum Exportieren in Google Cloud Storage (GCS) aus.Führen Sie das Skript in der VM oder auf dem lokalen Computer aus, um GCS-Daten in die interne Stage von Snowflake zu kopieren. Wir könnten auch direkt aus GCS mit einer Speicherintegration lesen, aber dies erfordert eine weitere Ebene der sicheren Zugriffskonfiguration (die für Ihren Anwendungsfall möglicherweise vorzuziehen ist).
Generieren Sie manuell
CREATE TABLEDDL mit den richtigen Spaltendatentypen und führen Sie sie in Snowflake aus.Führen Sie eine
COPY-Abfrage in Snowflake aus, um bereitgestellte Dateien zu importieren.Optional temporäre Daten in GCP und Internal Stage bereinigen (löschen).
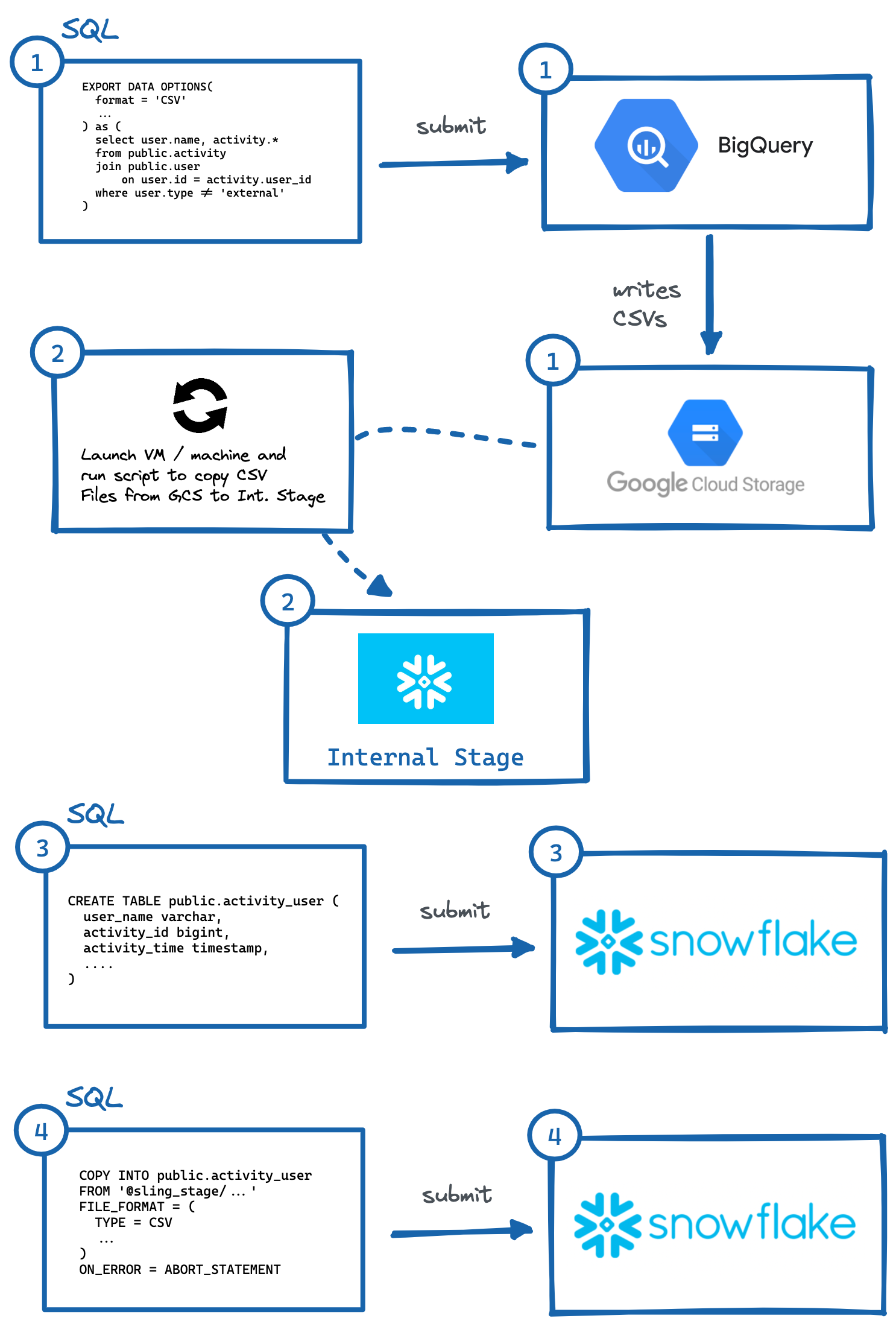 Bild: Schritte zum manuellen Exportieren von BigQuery nach Snowflake.
Bild: Schritte zum manuellen Exportieren von BigQuery nach Snowflake.Wie oben gezeigt, gibt es mehrere Schritte, um dies zu erreichen, wobei mit unabhängigen Systemen interagiert werden muss. Dies kann umständlich zu automatisieren sein, insbesondere das Generieren der richtigen DDL (Nr. 3) mit den richtigen Spaltentypen im Zielsystem (was ich persönlich am mühsamsten finde, versuchen Sie dies für Tabellen mit mehr als 50 Spalten).
Glücklicherweise gibt es einen einfacheren Weg, dies zu tun, und zwar durch die Verwendung eines raffinierten Tools namens Sling. Sling ist ein Datenintegrationstool, das eine einfache und effiziente Übertragung von Daten (Extract & Load) von/zu Datenbanken, Speicherplattformen und SaaS-Anwendungen ermöglicht. Es gibt zwei Möglichkeiten, es zu verwenden: Sling CLI und Sling Cloud. Wir werden das gleiche Verfahren wie oben durchführen, aber nur, indem wir Eingaben für Sling bereitstellen, und es wird automatisch die komplizierten Schritte für uns erledigen!
Sling-CLI verwenden
Wenn Sie ein Fanatiker der Befehlszeile sind, ist Sling CLI genau das Richtige für Sie. Es ist in go integriert (was es superschnell macht) und funktioniert mit Dateien, Datenbanken und verschiedenen SaaS-Endpunkten. Es kann auch mit Unix Pipes arbeiten (liest die Standardeingabe und schreibt in die Standardausgabe). Wir können es schnell von unserer Shell aus installieren:
# Auf dem Mac
brew install slingdata-io/sling/sling
# Unter Windows Powershell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Verwenden von Python Wrapper über Pip
pip install sling
Weitere Installationsoptionen (einschließlich Linux) finden Sie hier. Es gibt auch eine Python-Wrapper-Bibliothek, die nützlich ist, wenn Sie lieber mit Sling innerhalb von Python interagieren.
Nach der Installation sollten wir in der Lage sein, den Befehl sling auszuführen, der uns diese Ausgabe liefern sollte:
sling - An Extract-Load tool | https://slingdata.io/de
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Jetzt gibt es viele Möglichkeiten, Aufgaben zu konfigurieren, aber für unseren Anwendungsbereich in diesem Artikel müssen wir zuerst Verbindungsanmeldeinformationen für BigQuery und Snowflake hinzufügen (eine einmalige Aufgabe). Wir können dies tun, indem wir die Datei ~/.sling/env.yaml öffnen und die Anmeldeinformationen hinzufügen, die so aussehen sollten:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
Super, jetzt testen wir unsere Verbindungen:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Fantastisch, jetzt, da wir unsere Verbindungen eingerichtet haben, können wir unsere Aufgabe ausführen:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
Wow, das war einfach! Sling hat alle Schritte, die wir zuvor beschrieben haben, automatisch durchgeführt. Wir können die Snowflake-Daten sogar zurück in unsere Shell-sdtout (im CSV-Format) exportieren, indem wir nur die Tabellenkennung (public.activity_user) für das --src-stream-Flag angeben und die Zeilen zählen, um unsere Daten zu validieren:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Verwenden von Sling Cloud
Machen wir jetzt dasselbe mit der Sling Cloud-App. Sling Cloud verwendet die gleiche Engine wie Sling CLI, mit der Ausnahme, dass es sich um eine vollständig gehostete Plattform handelt, um alle Ihre Extract-Load-Anforderungen zu einem wettbewerbsfähigen Preis auszuführen (siehe unsere [Preisseite](https://slingdata.io/de/ Preisgestaltung)). Mit Sling Cloud können wir:
Arbeiten Sie mit vielen Teammitgliedern zusammen
Mehrere Arbeitsbereiche/Projekte verwalten
Schedule Extract-Load (EL) Tasks zur Ausführung in Intervallen oder zu festen Zeiten (CRON)
Sammeln und analysieren Sie Protokolle zum Debuggen
Fehlermeldungen per E-Mail oder Slack – Ausführung aus weltweiten Regionen oder im selbstgehosteten Modus, falls gewünscht (wobei Sling Cloud der Orchestrator ist).
Intuitive Benutzeroberfläche (UI) für schnelle Einrichtung und Ausführung
Als erstes müssen Sie sich hier für ein kostenloses Konto anmelden. Nach dem Einloggen können wir den
Cloud Mode-Modus auswählen (mehr zumSelf-Hosted-Modus später). Jetzt können wir ähnliche Schritte wie oben ausführen, jedoch mit der Sling Cloud-Benutzeroberfläche:
Hinzufügen der BigQuery-Verbindung
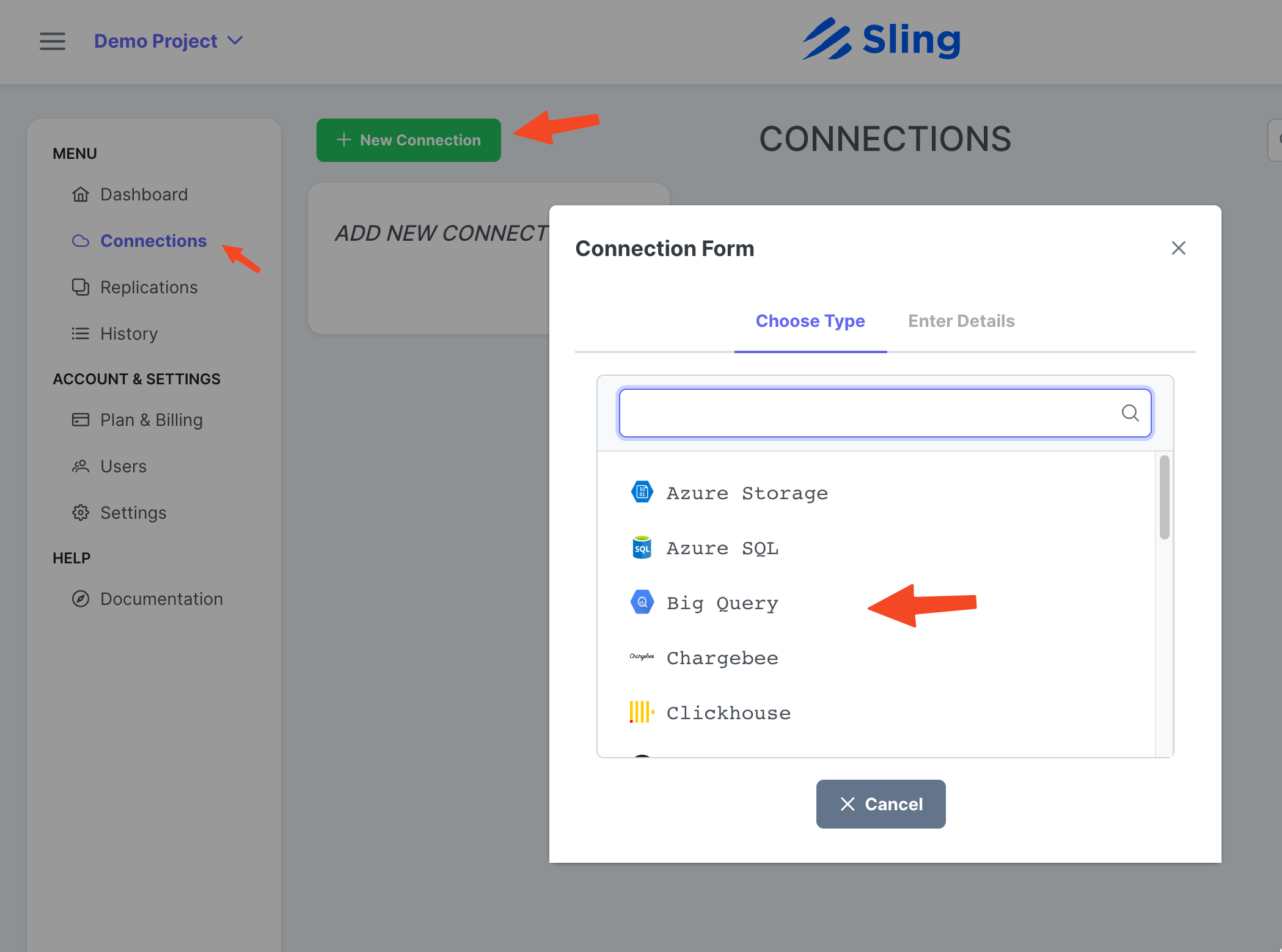
Schritte mit Screenshots
Gehen Sie zu Connections, klicken Sie auf New Connection, wählen Sie Big Query.
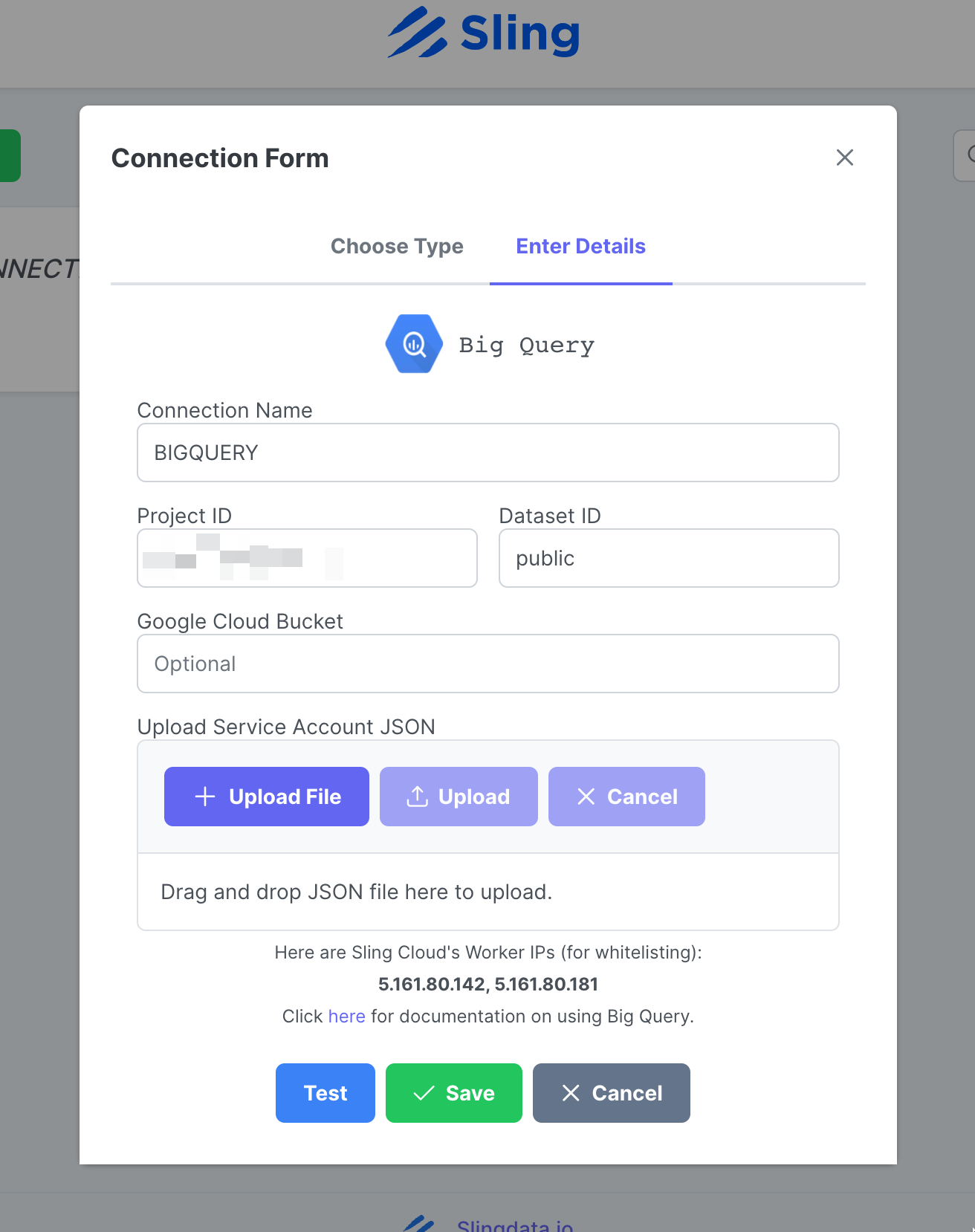
Geben Sie den Namen BIGQUERY und Ihre Anmeldeinformationen ein und laden Sie die JSON-Datei Ihres Google-Kontos hoch. Klicken Sie auf Test, um die Verbindung zu testen, und dann auf Save.
Hinzufügen der Snowflake-Verbindung
Schritte mit Screenshots
Klicken Sie auf New Connection, wählen Sie Snowflake.
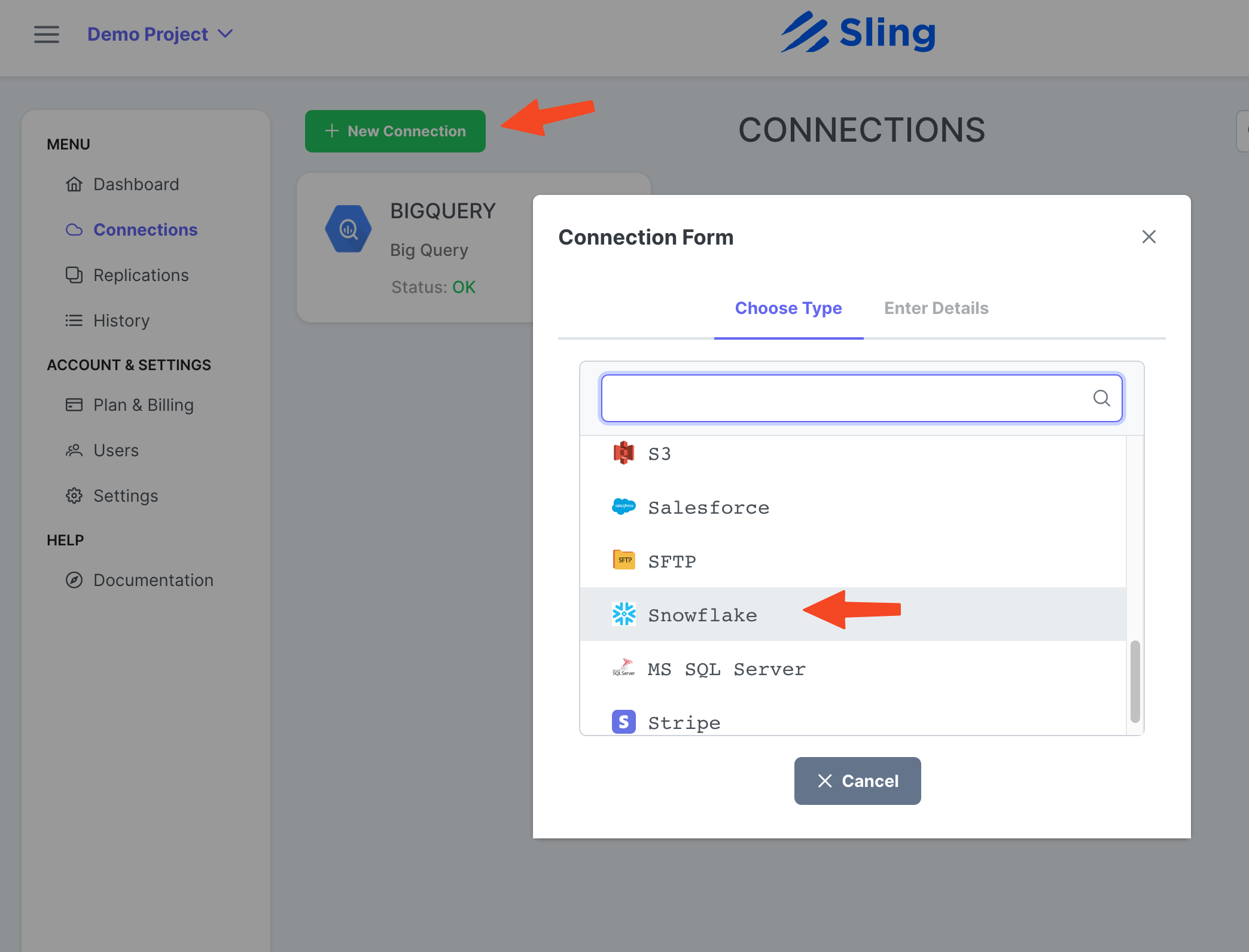
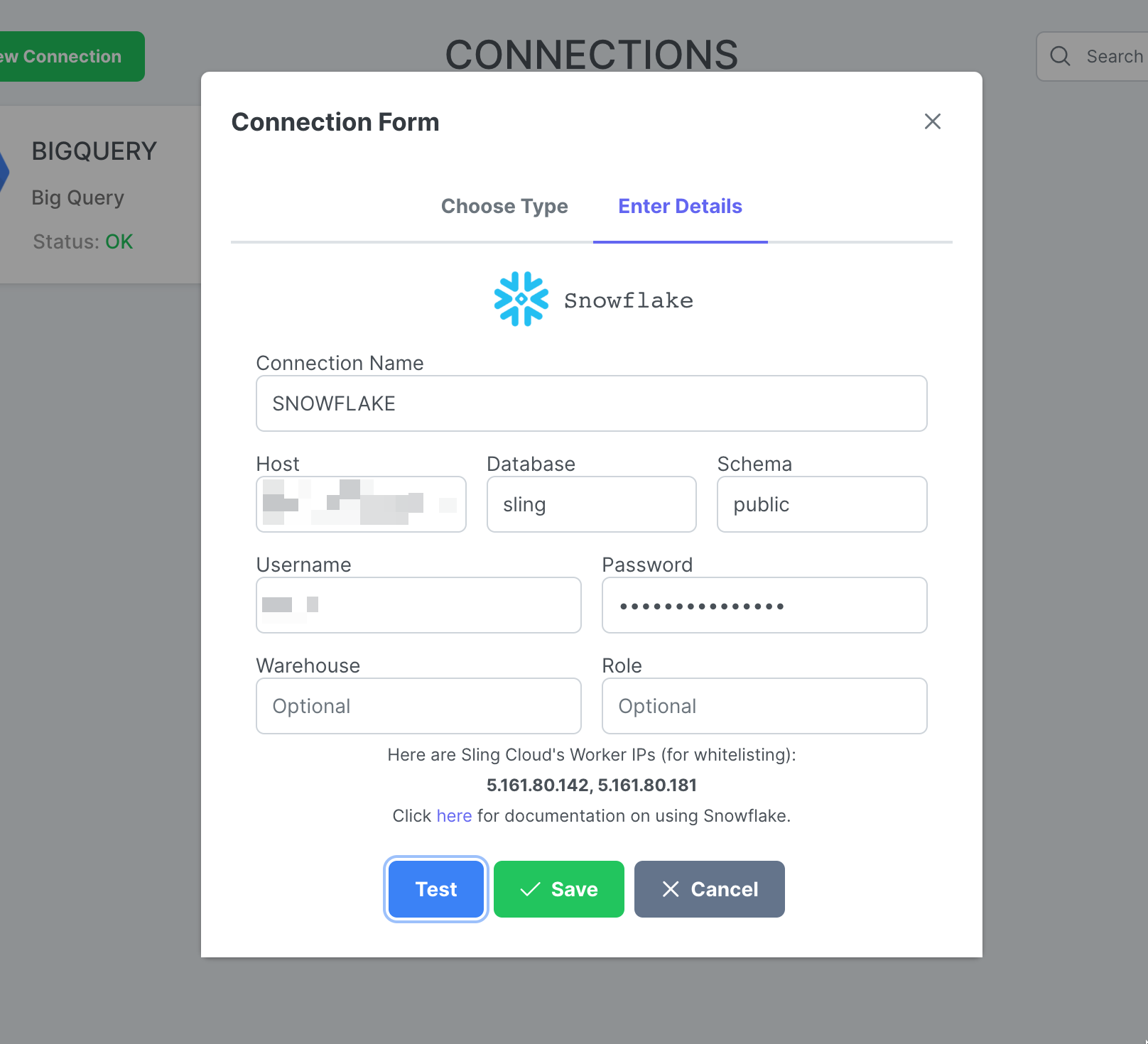
Geben Sie den Namen SNOWFLAKE und Ihre Anmeldeinformationen ein. Klicken Sie auf Test, um die Verbindung zu testen, und dann auf Save.
Replikation erstellen
Schritte mit Screenshots
Gehen Sie zu Replications, klicken Sie auf New Replication, wählen Sie Big Query als Quelle und Snowflake als Ziel. Klicken Next.
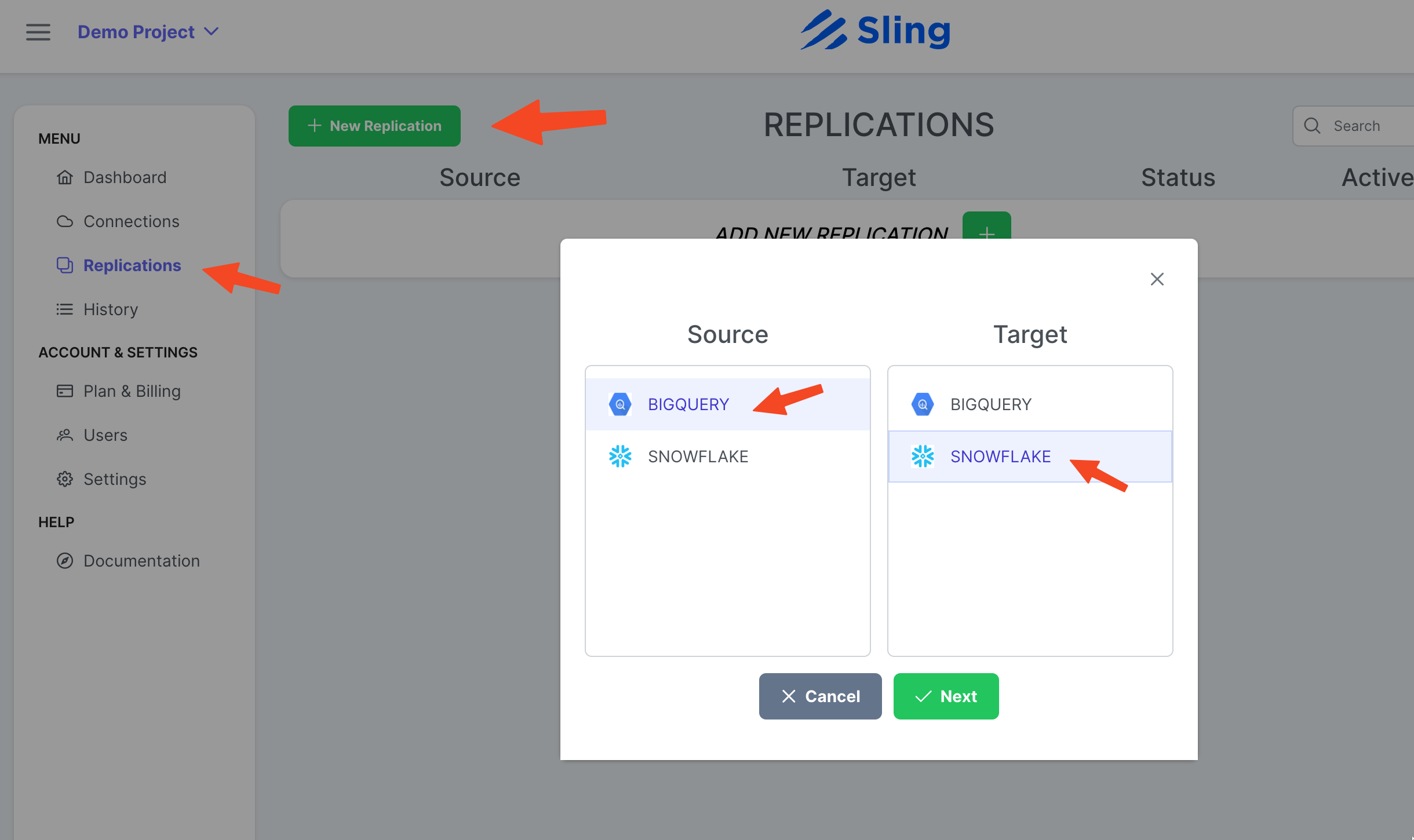
Stellen Sie bei Bedarf Target Object Name Pattern ein und klicken Sie auf Create.

Aufgabe erstellen und ausführen
Schritte mit Screenshots
Gehen Sie zur Registerkarte Streams, klicken Sie auf New SQL Stream, da wir eine benutzerdefinierte SQL als Quelldaten verwenden. Gib ihm einen Namen (activity_user). Fügen Sie die SQL-Abfrage ein und klicken Sie auf Ok.
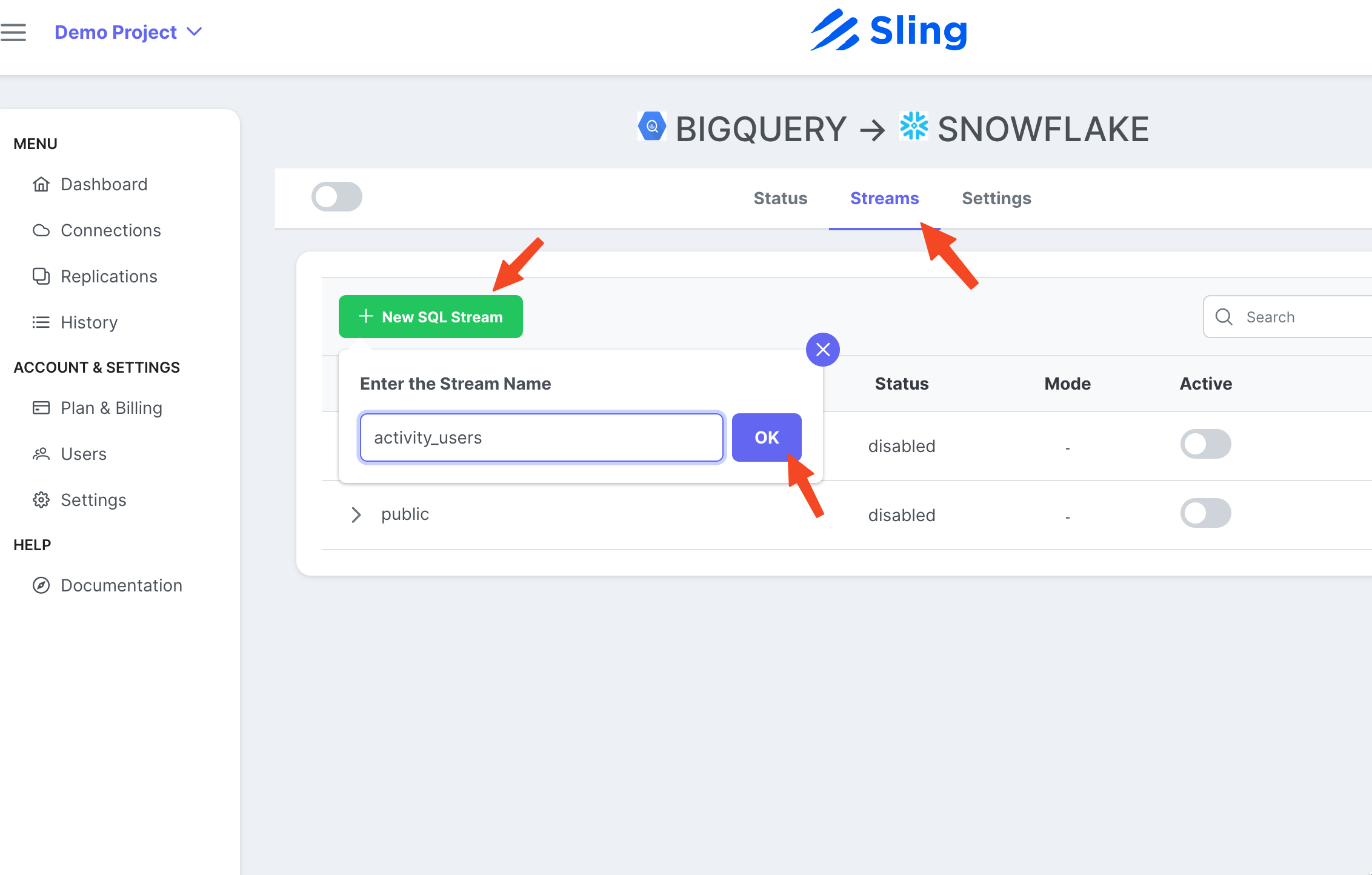
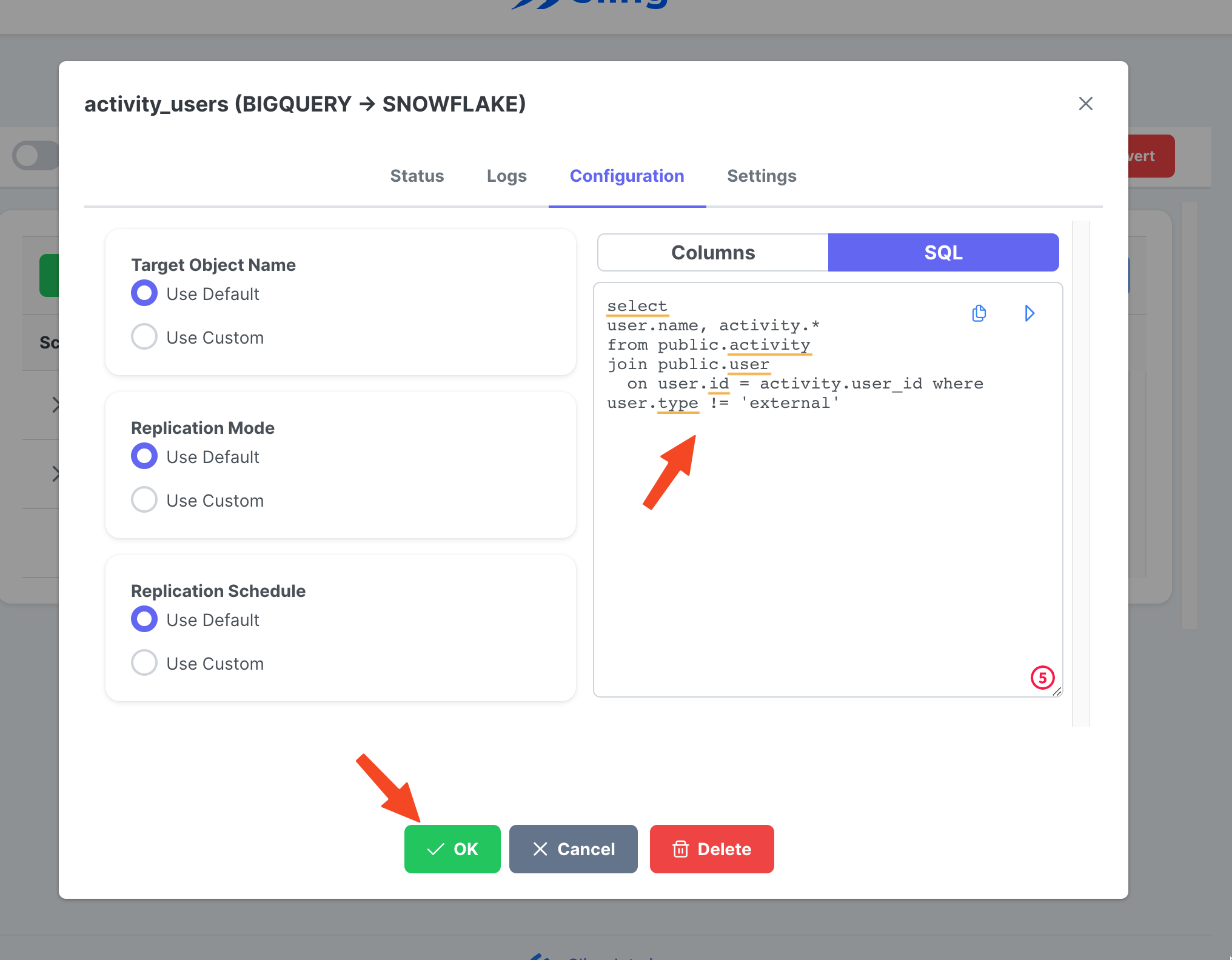
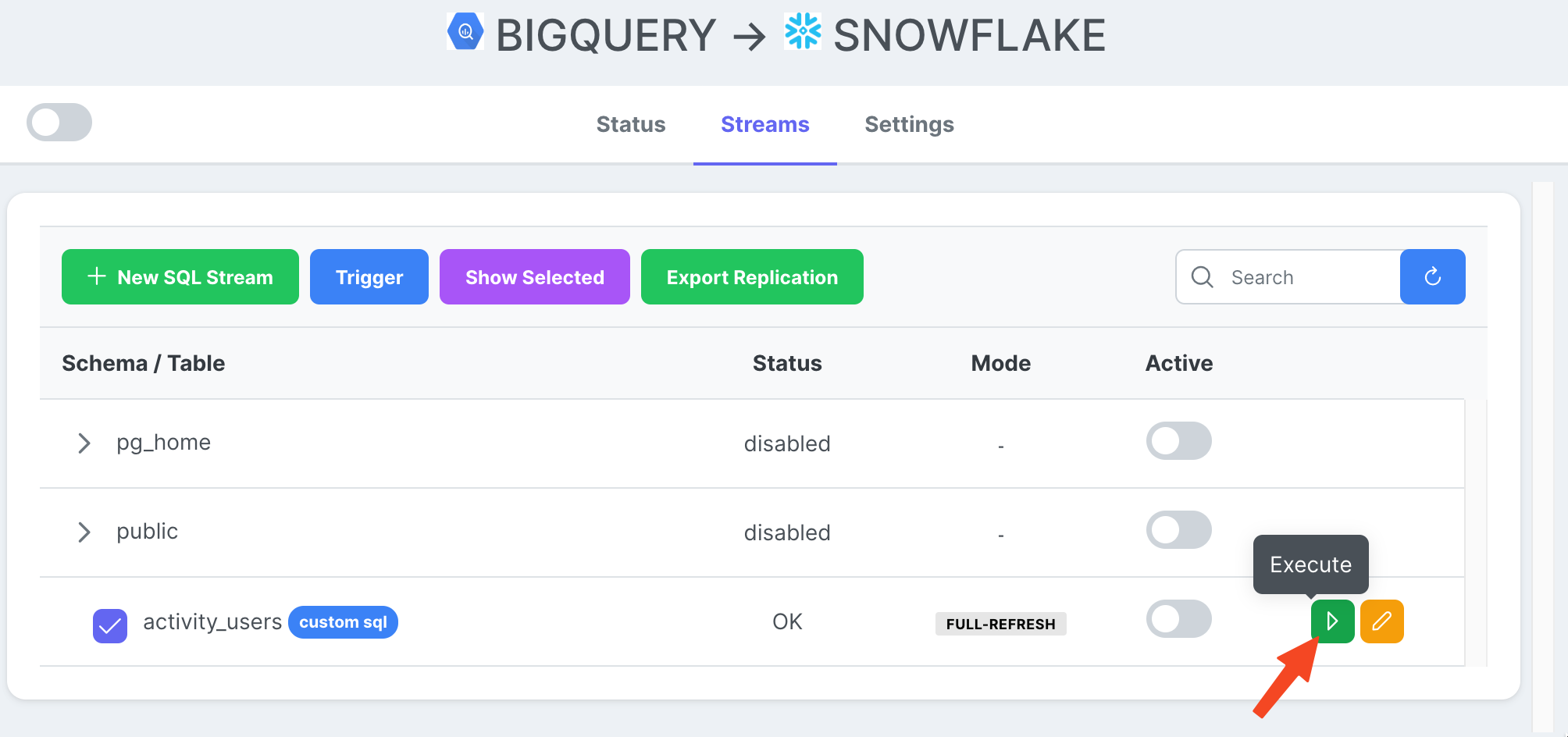
Jetzt, da wir eine Stream-Aufgabe bereit haben, können wir auf das Play-Symbol klicken, um sie auszulösen.
Sobald die Aufgabenausführung abgeschlossen ist, können wir die Protokolle überprüfen.
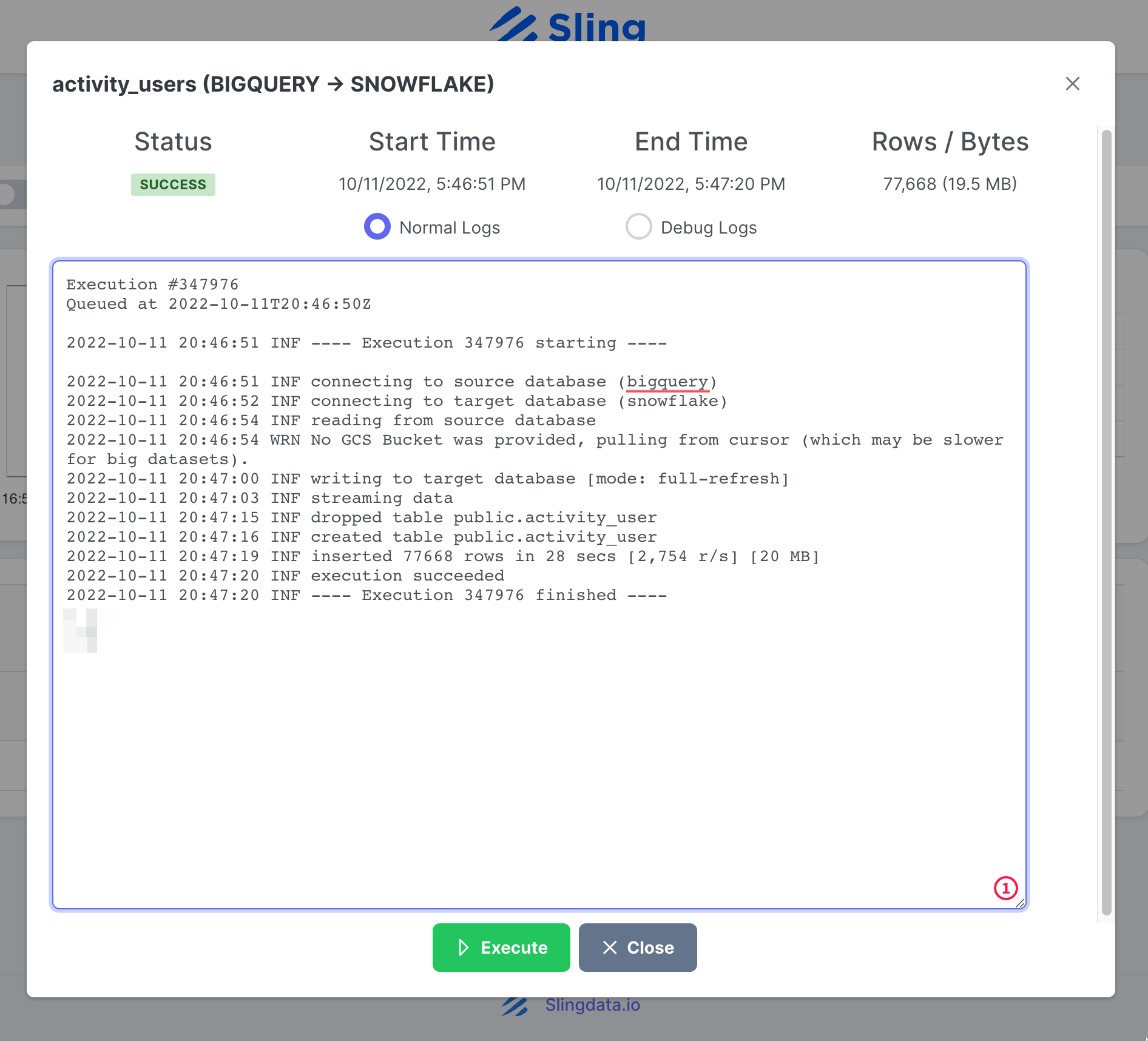
Das ist es! Wir haben unsere Aufgabe eingerichtet und können sie bei Bedarf erneut ausführen oder nach einem Zeitplan festlegen. Wie Sie vielleicht bemerken, erledigt Sling Cloud ein paar Dinge mehr für uns und bietet UI-orientierten Benutzern eine bessere Erfahrung im Vergleich zu Sling CLI.
Fazit
Wir befinden uns in einer Zeit, in der Daten Gold wert sind, und das Verschieben von Daten von einer Plattform auf eine andere sollte nicht schwierig sein. Wie wir gezeigt haben, bietet Sling eine leistungsstarke Alternative, indem es Reibungsverluste im Zusammenhang mit der Datenintegration reduziert. In einem anderen Beitrag behandeln wir das Exportieren aus Snowflake und das Laden in BigQuery.

