
Armazéns de Dados em Nuvem
Nos últimos anos, vimos um rápido crescimento no uso de data warehouses em nuvem (assim como o paradigma "warehouse-first"). Duas plataformas DWH em nuvem populares são BigQuery e Snowflake. Confira o gráfico abaixo para ver sua evolução ao longo do tempo.
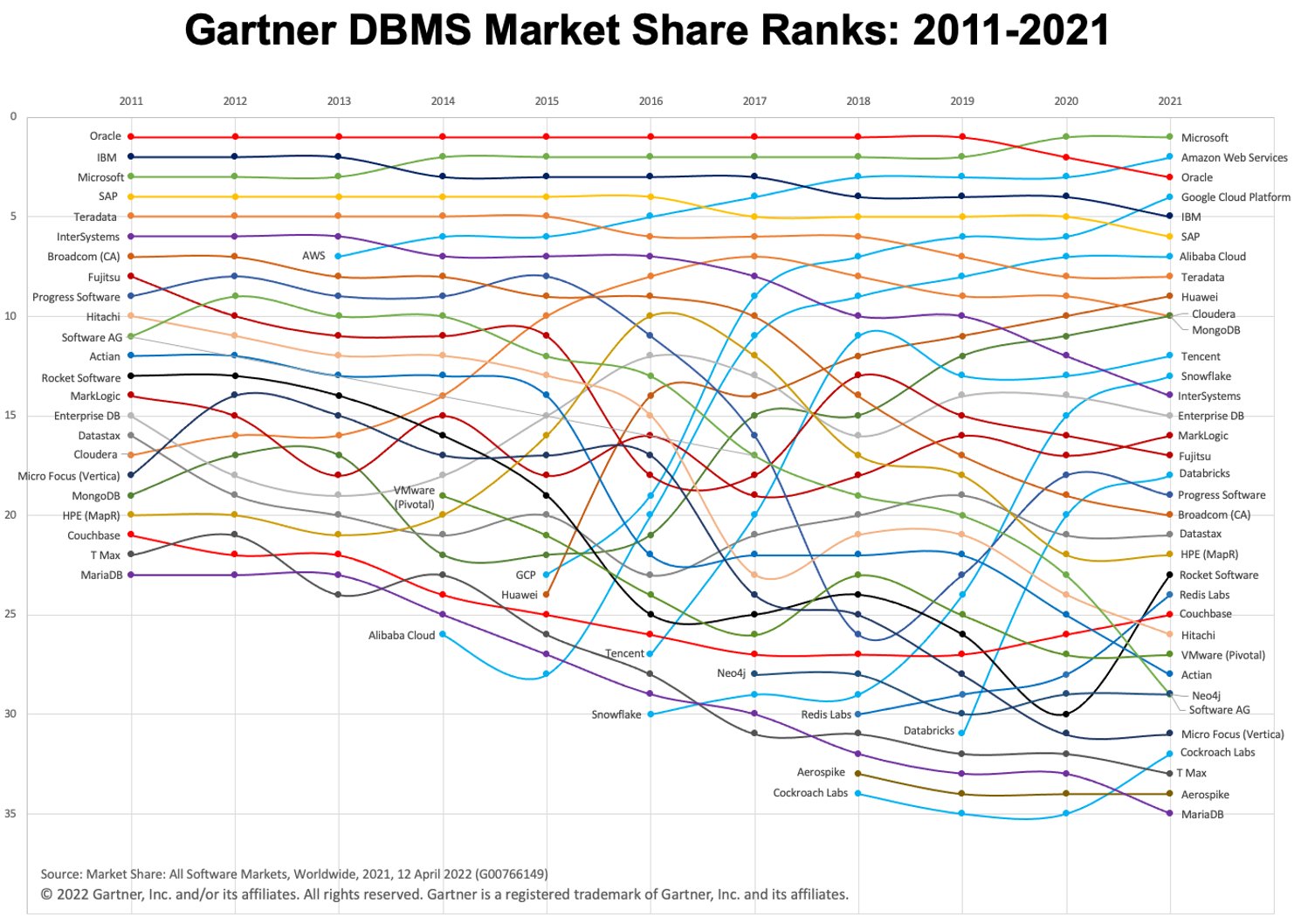 Imagem: Gartner via Adam Ronthal (@aronthal) no Twitter.
Imagem: Gartner via Adam Ronthal (@aronthal) no Twitter.
BigQuery, em 4º lugar em 2021, é um serviço de armazenamento de dados sem servidor totalmente gerenciado oferecido pelo Google Cloud Platform (GCP). Ele permite uma análise fácil e escalável em petabytes de dados e é conhecido há muito tempo por sua facilidade de uso e natureza livre de manutenção.
Snowflake, é um serviço similar oferecido pela empresa Snowflake Inc. Uma das principais diferenças é que o Snowflake permite hospedar a instância em Amazon Web Services (AWS), Azure (Microsoft) ou GCP (Google). Essa é uma grande vantagem se você já estiver estabelecido em um ambiente não GCP.
Exportando e Carregando os dados
Conforme as circunstâncias, às vezes é necessário ou desejado copiar dados de um ambiente BigQuery para um ambiente Snowflake. Vamos dar uma olhada e detalhar as várias etapas lógicas necessárias para mover adequadamente esses dados, pois nenhum dos serviços concorrentes possui uma função integrada para fazer isso facilmente. Para o nosso exemplo, vamos supor que nosso ambiente Snowflake de destino está hospedado na AWS.
Procedimento Passo a Passo
Para migrar dados do BigQuery para o Snowflake (AWS), estas são as etapas essenciais:
Identifique a tabela ou consulta e execute a consulta
EXPORT DATA OPTIONSpara exportar para o Google Cloud Storage (GCS).Execute o script na VM ou máquina local para copiar os dados do GCS para o palco interno do Snowflake. Também poderíamos ler diretamente do GCS com uma integração de armazenamento, mas isso envolve outra camada de configuração de acesso seguro (que pode ser preferível para seu caso de uso).
Gere manualmente
CREATE TABLEDDL com os tipos de dados de coluna corretos e execute no Snowflake.Execute uma consulta
COPYno Snowflake para importar arquivos de teste.Opcionalmente, limpe (exclua) dados temporários no GCP e no Palco Interno.
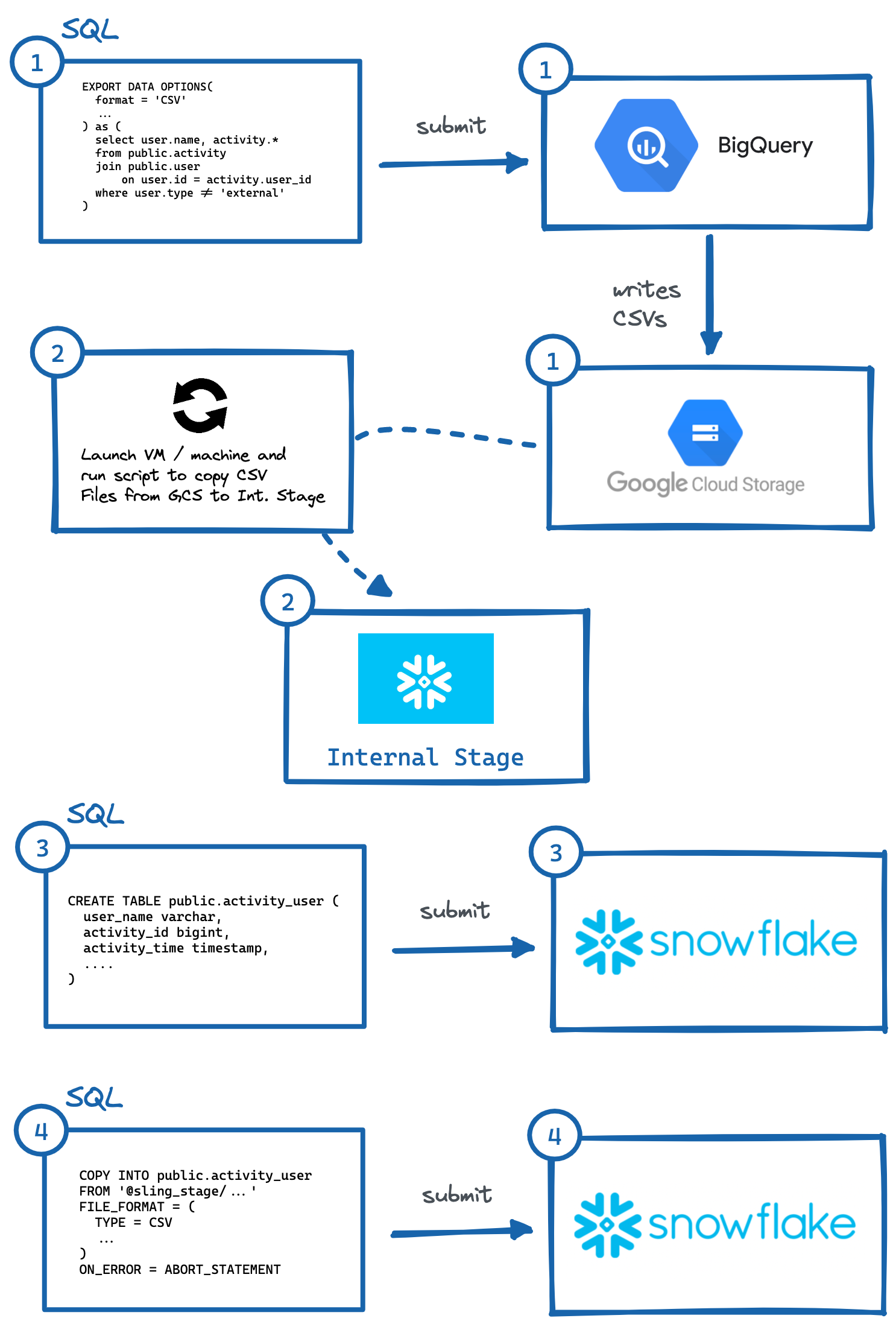 Imagem: etapas para exportar manualmente do BigQuery para o Snowflake.
Imagem: etapas para exportar manualmente do BigQuery para o Snowflake.Conforme demonstrado acima, existem várias etapas para que isso aconteça, onde sistemas independentes precisam interagir. Isso pode ser complicado para automatizar, especialmente gerando o DDL correto (#3) com os tipos de coluna apropriados no sistema de destino (o que eu pessoalmente acho mais trabalhoso, tente fazer isso para tabelas com mais de 50 colunas).
Felizmente, existe uma maneira mais fácil de fazer isso, e é usando uma ferramenta bacana chamada Sling. Sling é uma ferramenta de integração de dados que permite a movimentação fácil e eficiente de dados (Extrair e Carregar) de/para Bancos de Dados, Plataformas de Armazenamento e aplicativos SaaS. Existem duas maneiras de usá-lo: Sling CLI e Sling Cloud. Faremos o mesmo procedimento acima, mas apenas fornecendo entradas para o sling e ele fará automaticamente os passos intrincados para nós!
Usando Sling CLI
Se você é fanático por linha de comando, o Sling CLI é para você. Ele é integrado ao go (o que o torna super rápido) e funciona com arquivos, bancos de dados e vários endpoints saas. Ele também pode trabalhar com Unix Pipes (lê a entrada padrão e grava na saída padrão). Podemos instalá-lo rapidamente a partir do nosso shell:
# No Mac
brew install slingdata-io/sling/sling
# No Windows Powershell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Usando Python Wrapper via pip
pip install sling
Por favor, veja aqui para outras opções de instalação (incluindo Linux). Há também uma biblioteca Python wrapper, que é útil se você preferir interagir com o Sling dentro do Python.
Uma vez instalado, devemos ser capazes de executar o comando sling, que deve nos dar esta saída:
sling - An Extract-Load tool | https://slingdata.io/pt
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Agora, há muitas maneiras de configurar tarefas, mas para nosso escopo neste artigo, primeiro precisamos adicionar credenciais de conexão para BigQuery e Snowflake (uma tarefa de uma vez). Podemos fazer isso abrindo o arquivo ~/.sling/env.yaml e adicionando as credenciais, que devem ficar assim:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
Ótimo, agora vamos testar nossas conexões:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Fantástico, agora que temos nossas conexões configuradas, podemos executar nossa tarefa:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
Uau, isso foi fácil! O Sling fez todas as etapas que descrevemos anteriormente automaticamente. Podemos até exportar os dados do Snowflake de volta para nosso shell sdtout (no formato CSV) fornecendo apenas o identificador de tabela (public.activity_user) para o sinalizador --src-stream e contando as linhas para validar nossos dados:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Usando Sling Cloud
Agora vamos fazer o mesmo com o aplicativo Sling Cloud. O Sling Cloud usa o mesmo mecanismo que o Sling CLI, exceto que é uma plataforma totalmente hospedada para executar todas as suas necessidades de Extract-Load a um preço competitivo (confira nossa [página de preços](https://slingdata.io/pt/ preços)). Com o Sling Cloud, podemos:
Colabore com muitos membros da equipe
Gerenciar vários espaços de trabalho/projetos
Agendar Tarefas Extract-Load (EL) para serem executadas em um intervalo ou em horários fixos (CRON)
Colete e analise Logs para depuração
Notificações de erro via e-mail ou Slack
Executar a partir de regiões mundiais ou modo auto-hospedado, se desejado (onde Sling Cloud é o orquestrador).
Interface de usuário intuitiva (UI) para configuração e execução rápidas
A primeira coisa é se inscrever para uma conta gratuita aqui. Depois de fazer login, podemos selecionar o
Cloud Mode(mais sobre o modoSelf-Hostedposteriormente). Agora podemos executar etapas semelhantes às acima, mas usando a IU do Sling Cloud:
Adicionando a conexão do BigQuery
Passos com capturas de tela
Vá para Connections, clique em New Connection, selecione Big Query.
Insira o nome BIGQUERY, suas credenciais e carregue o arquivo JSON da sua conta do Google. Clique em Test para testar a conectividade e depois em Save.

Adicionando a Conexão Floco de Neve
Passos com capturas de tela
Clique em New Connection, selecione Snowflake.
Insira o nome SNOWFLAKE e suas credenciais. Clique em Test para testar a conectividade e depois em Save.
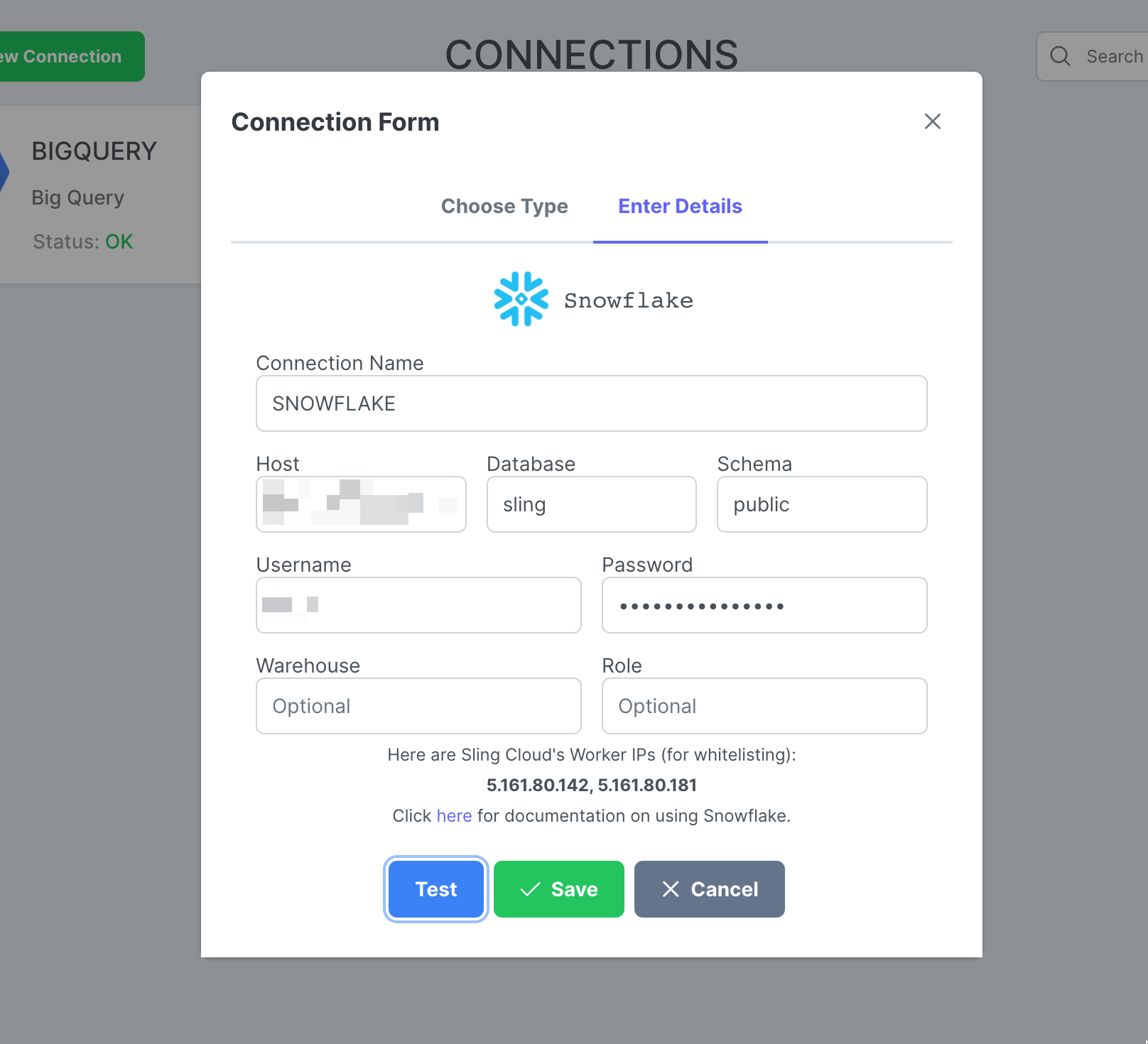
Criar replicação
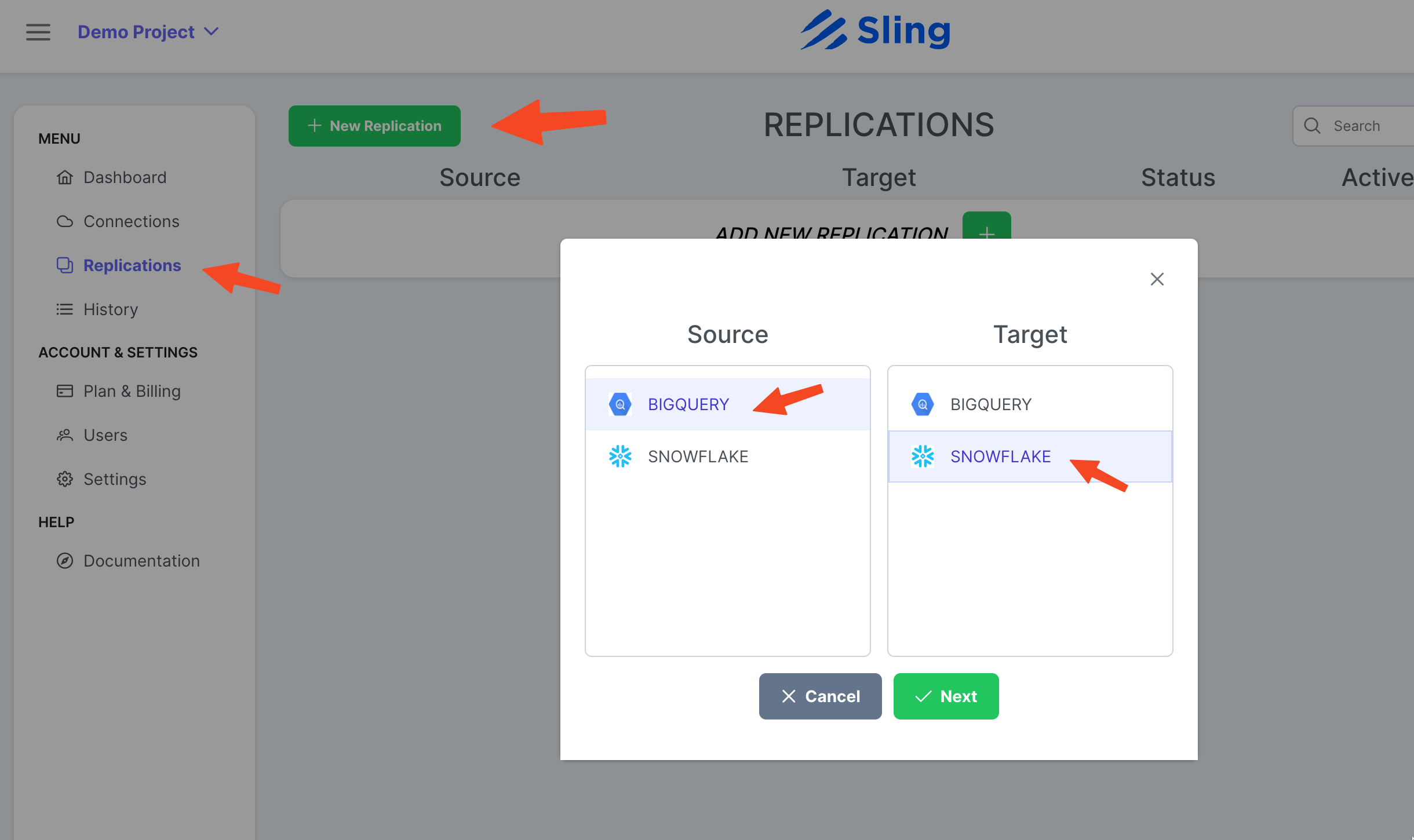
Passos com capturas de tela
Vá para Replications, clique em New Replication, selecione Big Query como origem e Snowflake como destino. Clique em Next.
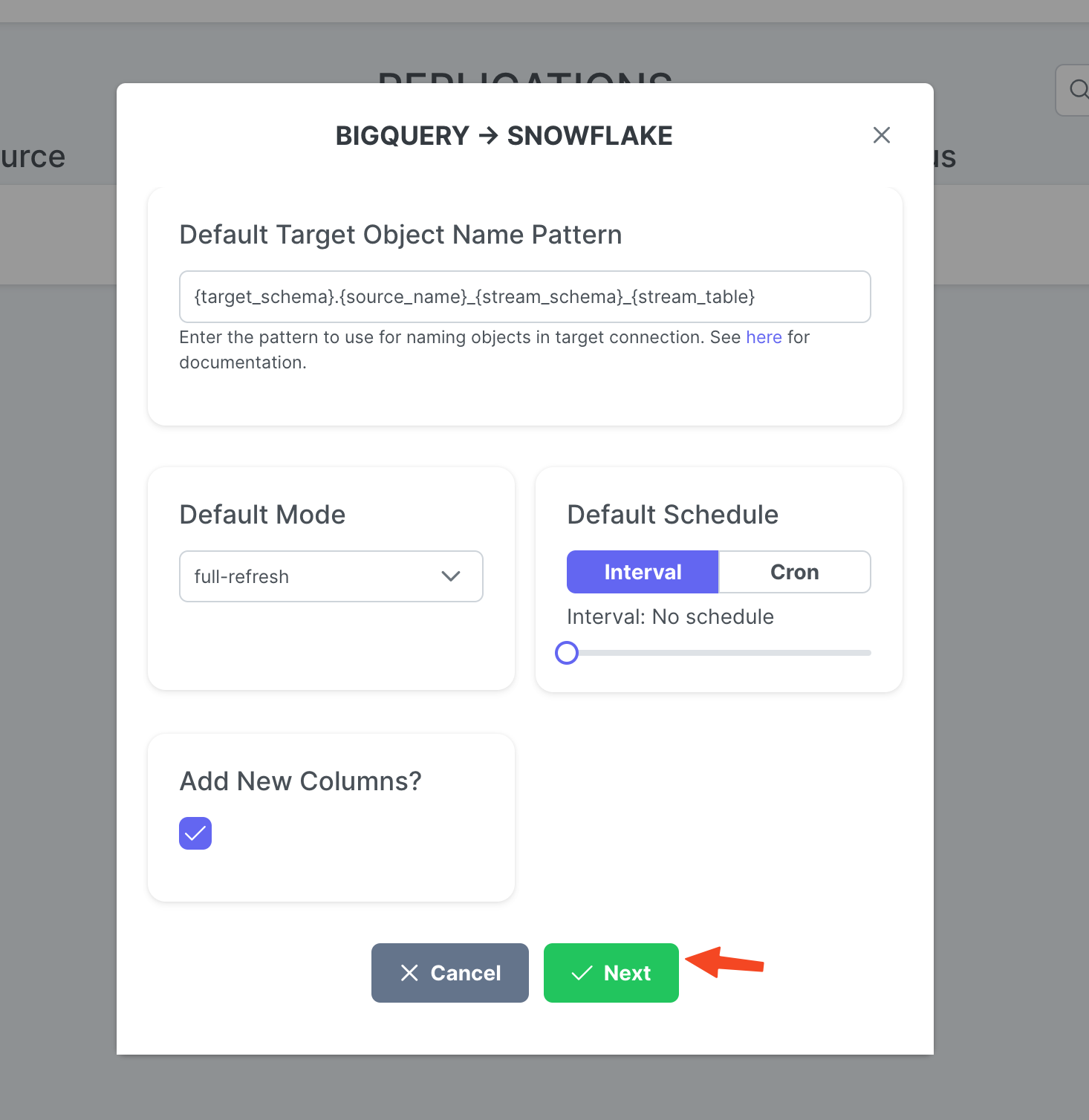
Ajuste para Target Object Name Pattern se desejar e clique em Create.
Criar e Executar Tarefa
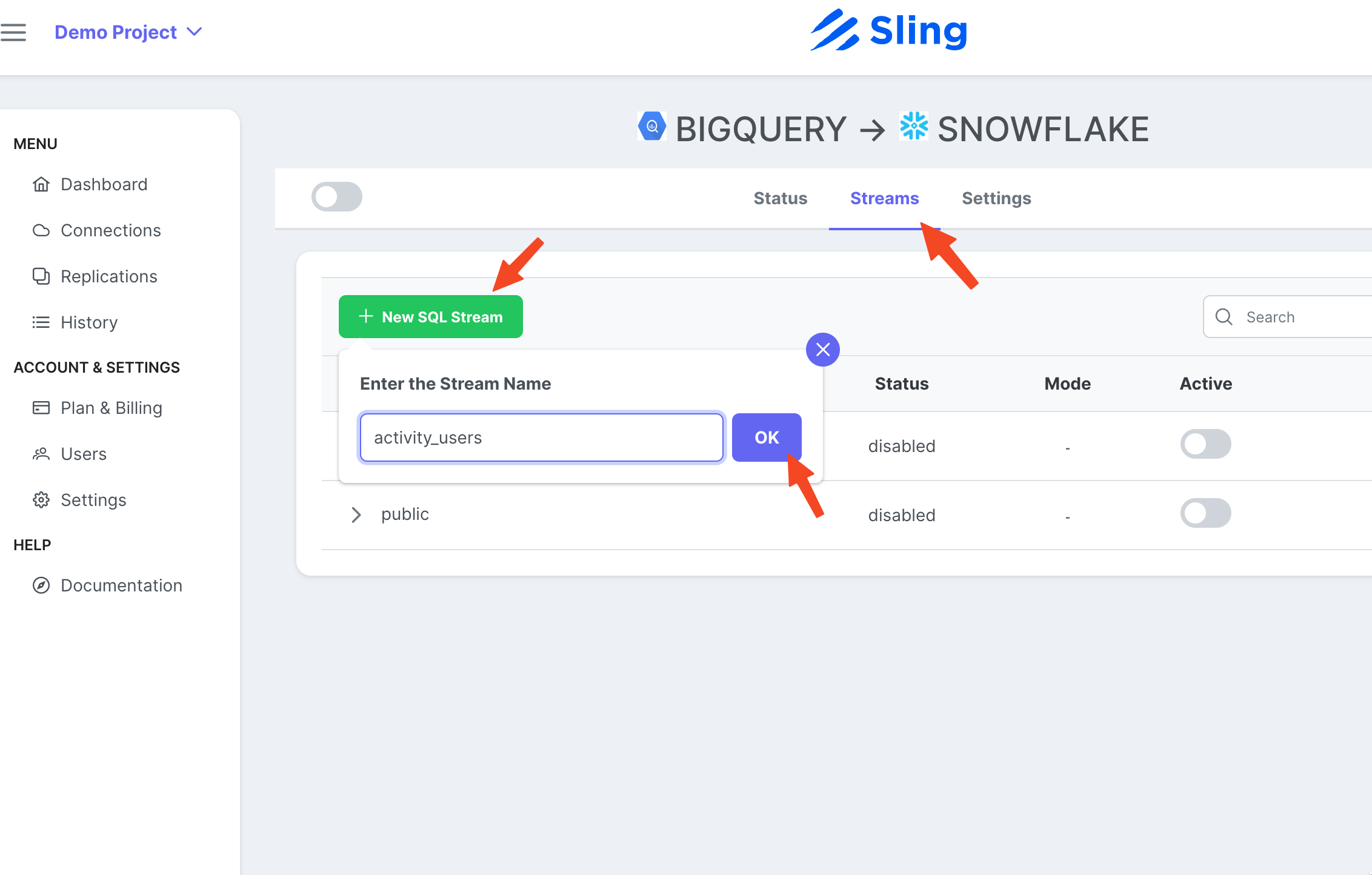
Passos com capturas de tela
Vá para a guia Streams, clique em New SQL Stream, pois estamos usando um SQL personalizado como os dados de origem. Dê um nome (activity_user). Cole a consulta SQL, clique em Ok.
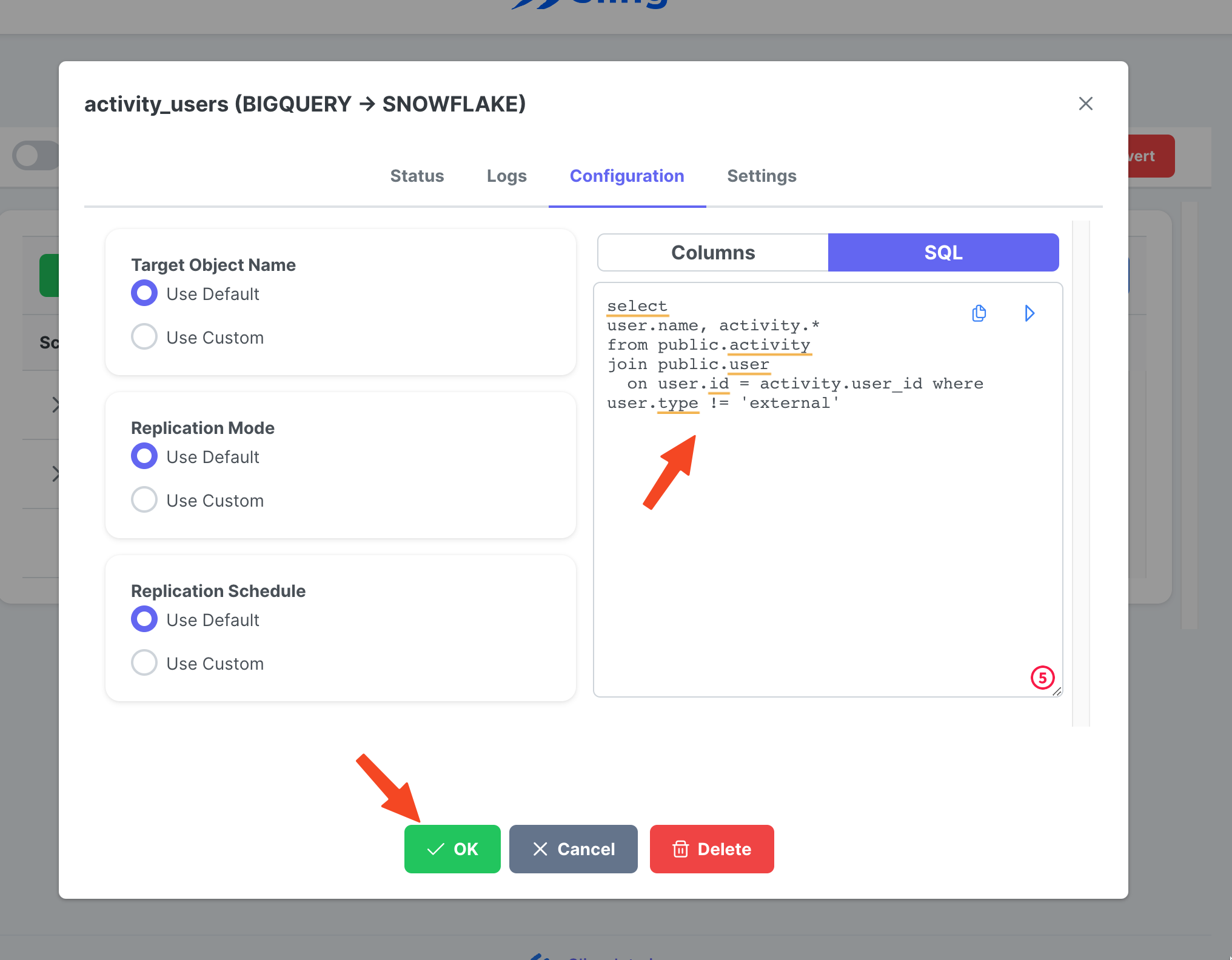
Agora que temos uma tarefa de fluxo pronta, podemos clicar no ícone Reproduzir para acioná-la.
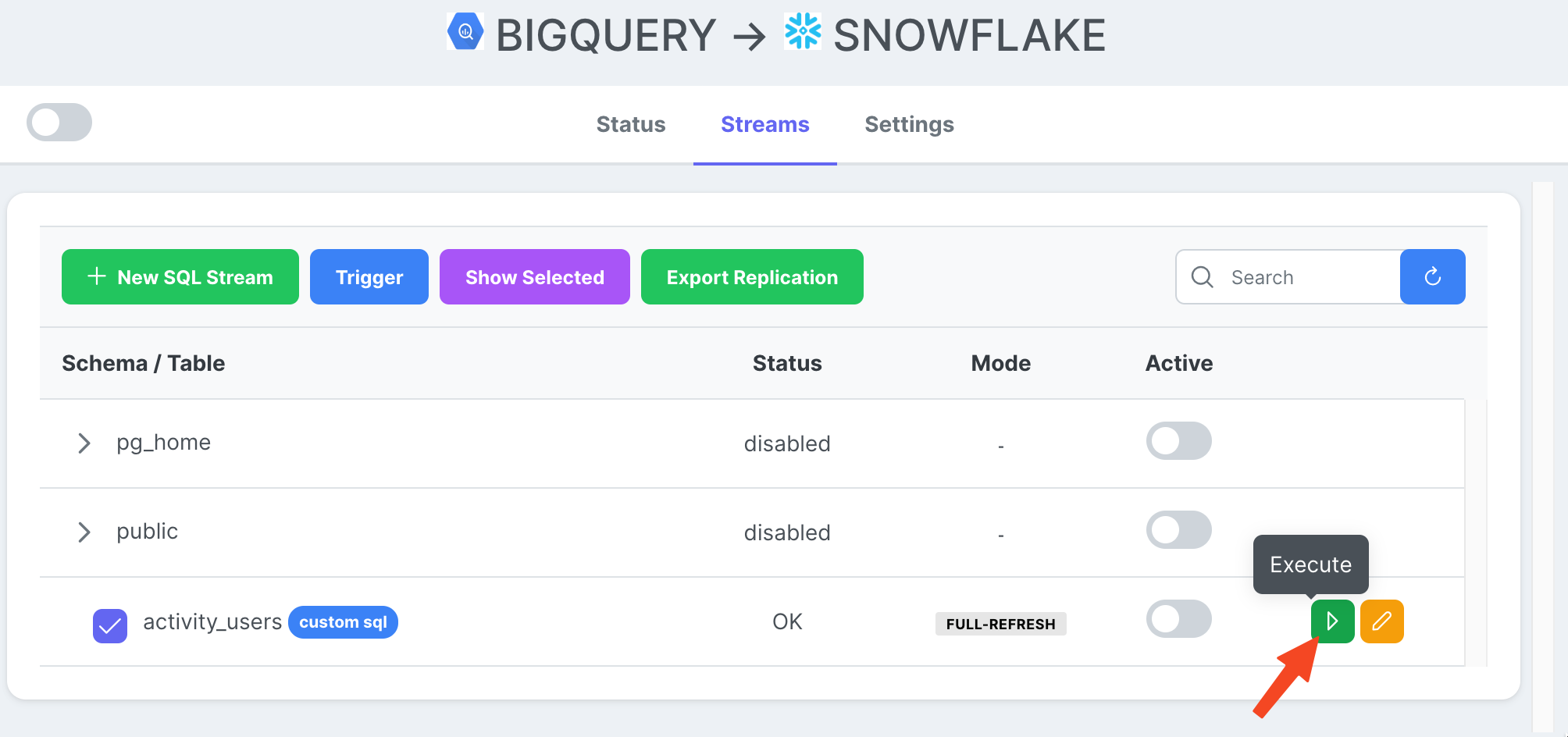
Assim que a execução da tarefa for concluída, podemos inspecionar os logs.
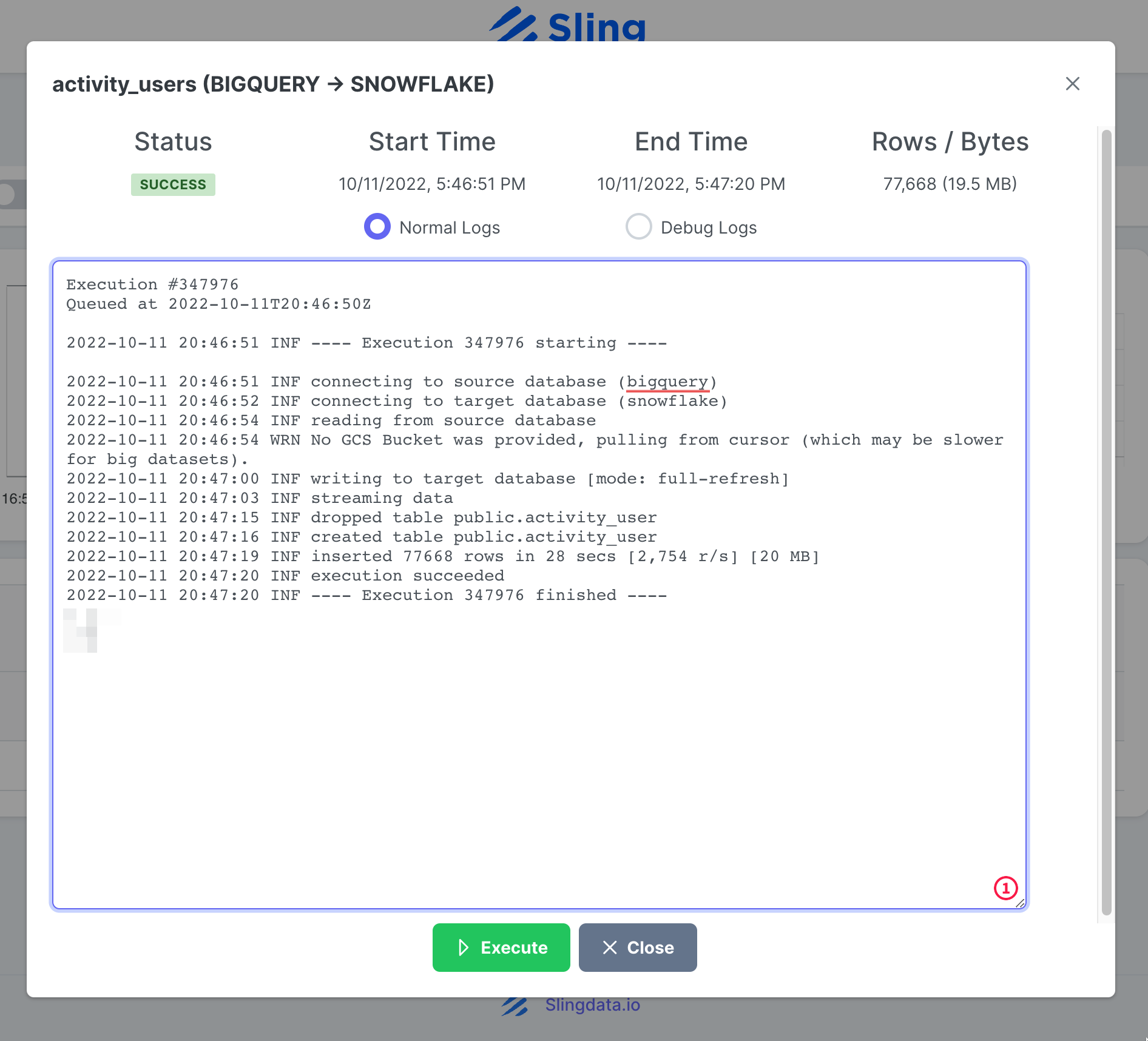
É isso! Temos nossa configuração de tarefa e podemos executá-la novamente sob demanda ou configurá-la em um cronograma. Como você pode notar, o Sling Cloud lida com mais algumas coisas para nós e oferece aos usuários orientados à interface do usuário uma experiência melhor em comparação com o Sling CLI.
Conclusão
Estamos em uma era em que dados valem ouro, e mover dados de uma plataforma para outra não deve ser difícil. Como demonstramos, o Sling oferece uma alternativa poderosa ao reduzir o atrito associado à integração de dados. Abordaremos como exportar do Snowflake e carregar no BigQuery em outra postagem.

