
Almacenes de datos en la nube
En los últimos años, hemos visto un rápido crecimiento en el uso de almacenes de datos en la nube (así como el paradigma de "warehouse-first"). Dos plataformas DWH en la nube populares son BigQuery y Snowflake. Consulte el siguiente gráfico para ver su evolución a lo largo del tiempo.
 Imagen: Gartner vía Adam Ronthal (@aronthal) en Twitter.
Imagen: Gartner vía Adam Ronthal (@aronthal) en Twitter.
BigQuery, que ocupa el puesto número 4 a partir de 2021, es un servicio de almacenamiento de datos sin servidor totalmente administrado que ofrece Google Cloud Platform (GCP). Permite un análisis fácil y escalable de petabytes de datos y es conocida desde hace mucho tiempo por su facilidad de uso y su naturaleza libre de mantenimiento.
Snowflake, es un servicio similar ofrecido por la empresa Snowflake Inc. Una de las principales diferencias es que Snowflake le permite alojar la instancia en Amazon Web Services (AWS), Azure (Microsoft) o GCP (Google). Esta es una gran ventaja si ya está establecido en un entorno que no es GCP.
Exportando y Cargando los datos
Según las circunstancias, a veces es necesario o se desea copiar datos de un entorno de BigQuery a un entorno de Snowflake. Echemos un vistazo y analicemos los diversos pasos lógicos necesarios para mover correctamente estos datos, ya que ninguno de los servicios de la competencia tiene una función integrada para hacerlo fácilmente. Por el bien de nuestro ejemplo, supondremos que nuestro entorno Snowflake de destino está alojado en AWS.
Procedimiento paso a paso
Para migrar datos de BigQuery a Snowflake (AWS), estos son los pasos esenciales:
Identifique la tabla o consulta y ejecute
EXPORT DATA OPTIONSconsulta para exportar a Google Cloud Storage (GCS).Ejecute el script en la máquina virtual o en la máquina local para copiar los datos de GCS en la etapa interna de Snowflake. También podríamos leer directamente desde GCS con una integración de almacenamiento, pero esto implica otra capa de configuración de acceso seguro (que puede ser preferible para su caso de uso).
Genere manualmente
CREATE TABLEDDL con los tipos de datos de columna correctos y ejecútelo en Snowflake.Ejecute una consulta
COPYen Snowflake para importar archivos preparados.Opcionalmente, limpie (elimine) los datos temporales en GCP y en la etapa interna.
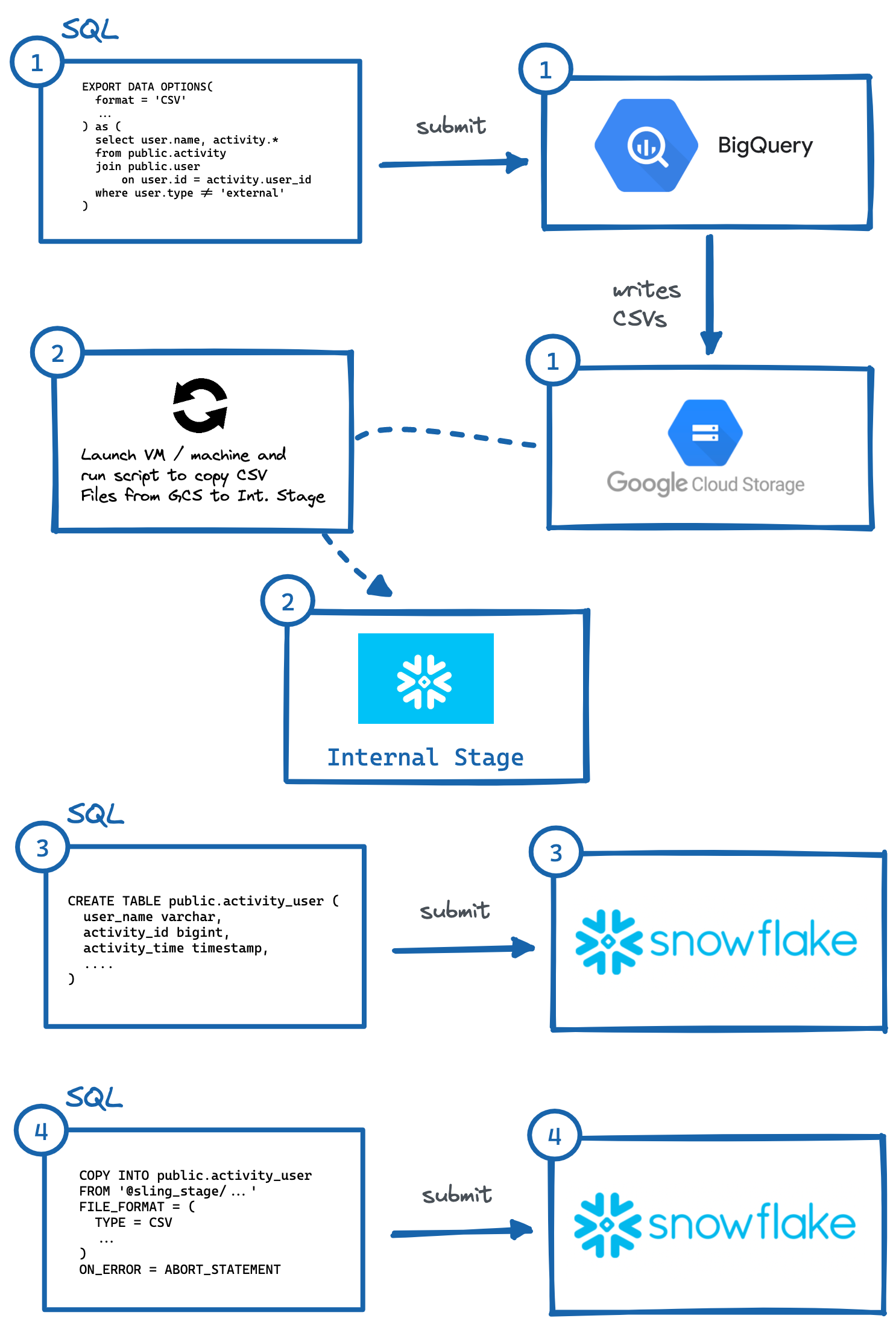 Imagen: Pasos para exportar manualmente de BigQuery a Snowflake.
Imagen: Pasos para exportar manualmente de BigQuery a Snowflake.Como se demostró anteriormente, hay varios pasos para que esto suceda, en los que es necesario interactuar con sistemas independientes. Esto puede ser engorroso de automatizar, especialmente generar el DDL correcto (n. ° 3) con los tipos de columna adecuados en el sistema de destino (lo que personalmente considero más engorroso, intente hacer esto para tablas con más de 50 columnas).
Afortunadamente, hay una manera más fácil de hacer esto, y es usando una ingeniosa herramienta llamada Sling. Sling es una herramienta de integración de datos que permite el movimiento fácil y eficiente de datos (Extracción y carga) desde/hacia bases de datos, plataformas de almacenamiento y aplicaciones SaaS. Hay dos formas de usarlo: Sling CLI y Sling Cloud. ¡Haremos el mismo procedimiento que el anterior, pero solo proporcionando entradas a sling y automáticamente hará los intrincados pasos por nosotros!
Uso de la CLI de Sling
Si eres un fanático de la línea de comandos, Sling CLI es para ti. Está integrado en go (lo que lo hace súper rápido) y funciona con archivos, bases de datos y varios puntos finales SaaS. También puede funcionar con Unix Pipes (lee la entrada estándar y escribe en la salida estándar). Podemos instalarlo rápidamente desde nuestro shell:
# En Mac
brew install slingdata-io/sling/sling
# En Windows PowerShell
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# Uso de Python Wrapper a través de pip
pip install sling
Consulte aquí para conocer otras opciones de instalación (incluido Linux). También hay una biblioteca envoltorio de Python, que es útil si prefiere interactuar con Sling dentro de Python.
Una vez instalado, deberíamos poder ejecutar el comando sling, que debería darnos este resultado:
sling - An Extract-Load tool | https://slingdata.io/es
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
Ahora hay muchas formas de configurar tareas, pero para nuestro alcance en este artículo, primero debemos agregar credenciales de conexión para BigQuery y Snowflake (una tarea de una sola vez). Podemos hacer esto abriendo el archivo ~/.sling/env.yaml y agregando las credenciales, que deberían verse así:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
Genial, ahora probemos nuestras conexiones:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
Fantástico, ahora que tenemos nuestras conexiones configuradas, podemos ejecutar nuestra tarea:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
¡Guau, eso fue fácil! Sling realizó todos los pasos que describimos anteriormente automáticamente. Incluso podemos exportar los datos de Snowflake a nuestro shell sdtout (en formato CSV) proporcionando solo el identificador de tabla (public.activity_user) para el indicador --src-stream y contar las líneas para validar nuestros datos:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
Uso de Sling Cloud
Ahora hagamos lo mismo con la aplicación Sling Cloud. Sling Cloud usa el mismo motor que Sling CLI, excepto que es una plataforma totalmente alojada para ejecutar todas sus necesidades de extracción y carga a un precio competitivo (consulte nuestra [página de precios] (https://slingdata.io/es/ precios)). Con Sling Cloud, podemos:
Colabora con muchos miembros del equipo
Administra múltiples espacios de trabajo/proyectos
Programar tareas de extracción-carga (EL) para que se ejecuten en un intervalo o tiempos fijos (CRON)
Recopilar y analizar registros para la depuración
Notificaciones de error por correo electrónico o Slack
Ejecutar desde regiones de todo el mundo o modo autohospedado si se desea (donde Sling Cloud es el orquestador).
Interfaz de usuario intuitiva (UI) para una configuración y ejecución rápidas
Lo primero es registrarse para obtener una cuenta gratuita aquí. Una vez que haya iniciado sesión, podemos seleccionar
Cloud Mode(más información sobre el modoSelf-Hostedmás adelante). Ahora podemos realizar pasos similares a los anteriores, pero usando la interfaz de usuario de Sling Cloud:
Agregar la conexión de BigQuery
Pasos con capturas de pantalla
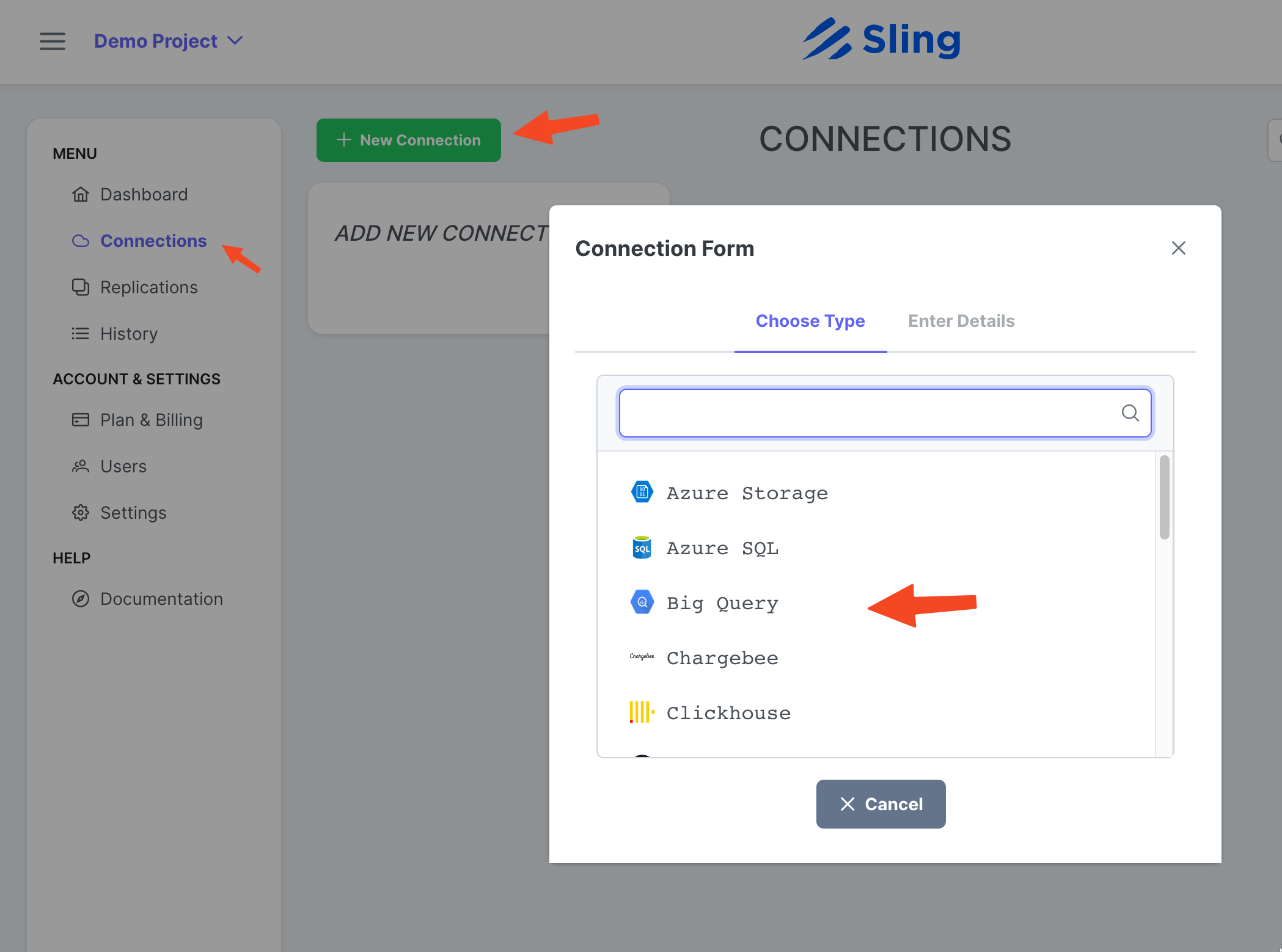
Vaya a Connections, haga clic en New Connection, seleccione Big Query.
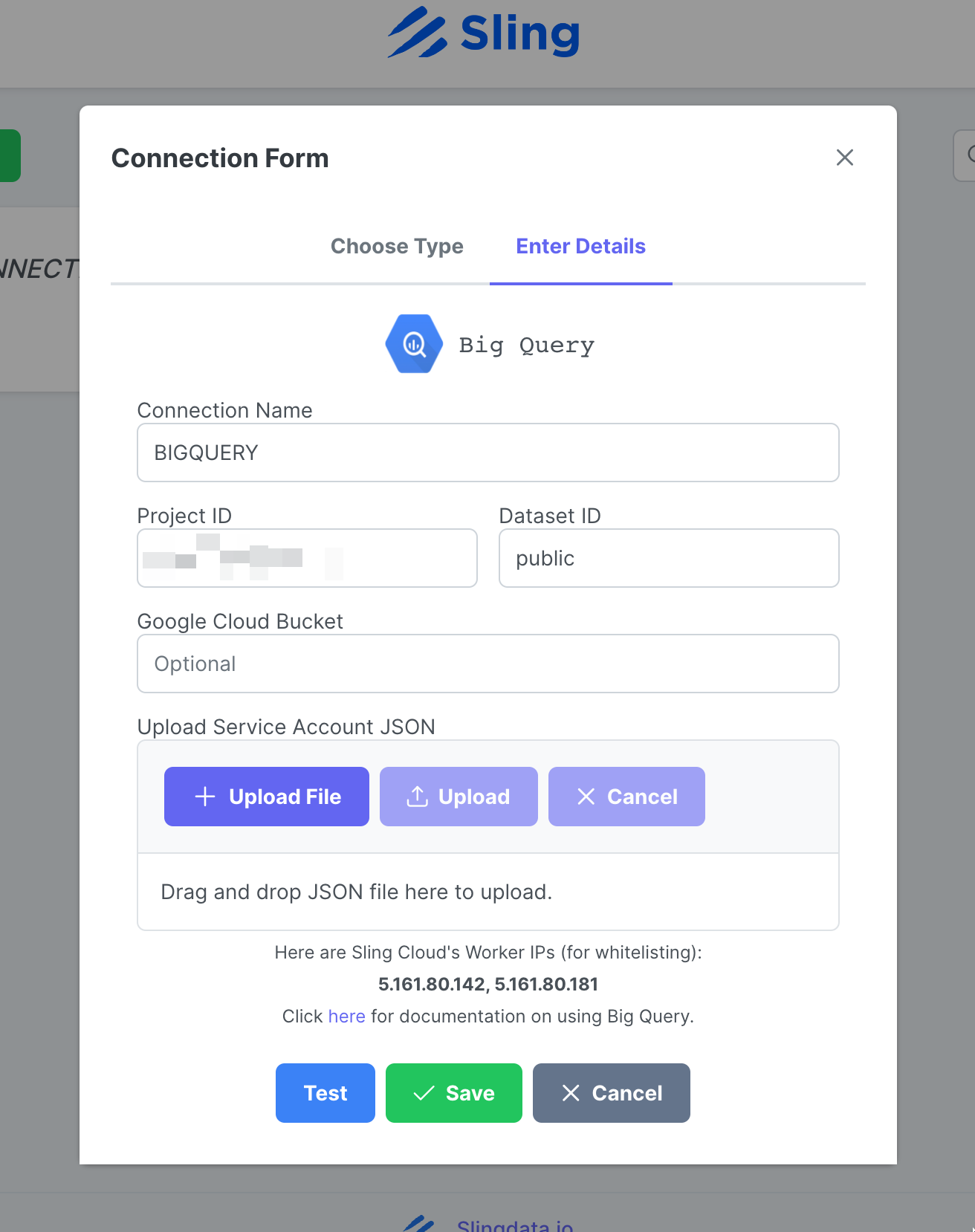
Ingrese el nombre BIGQUERY, sus credenciales y cargue el archivo JSON de su cuenta de Google. Haga clic en Test para probar la conectividad, luego Save.
Agregar la conexión de copo de nieve
Pasos con capturas de pantalla
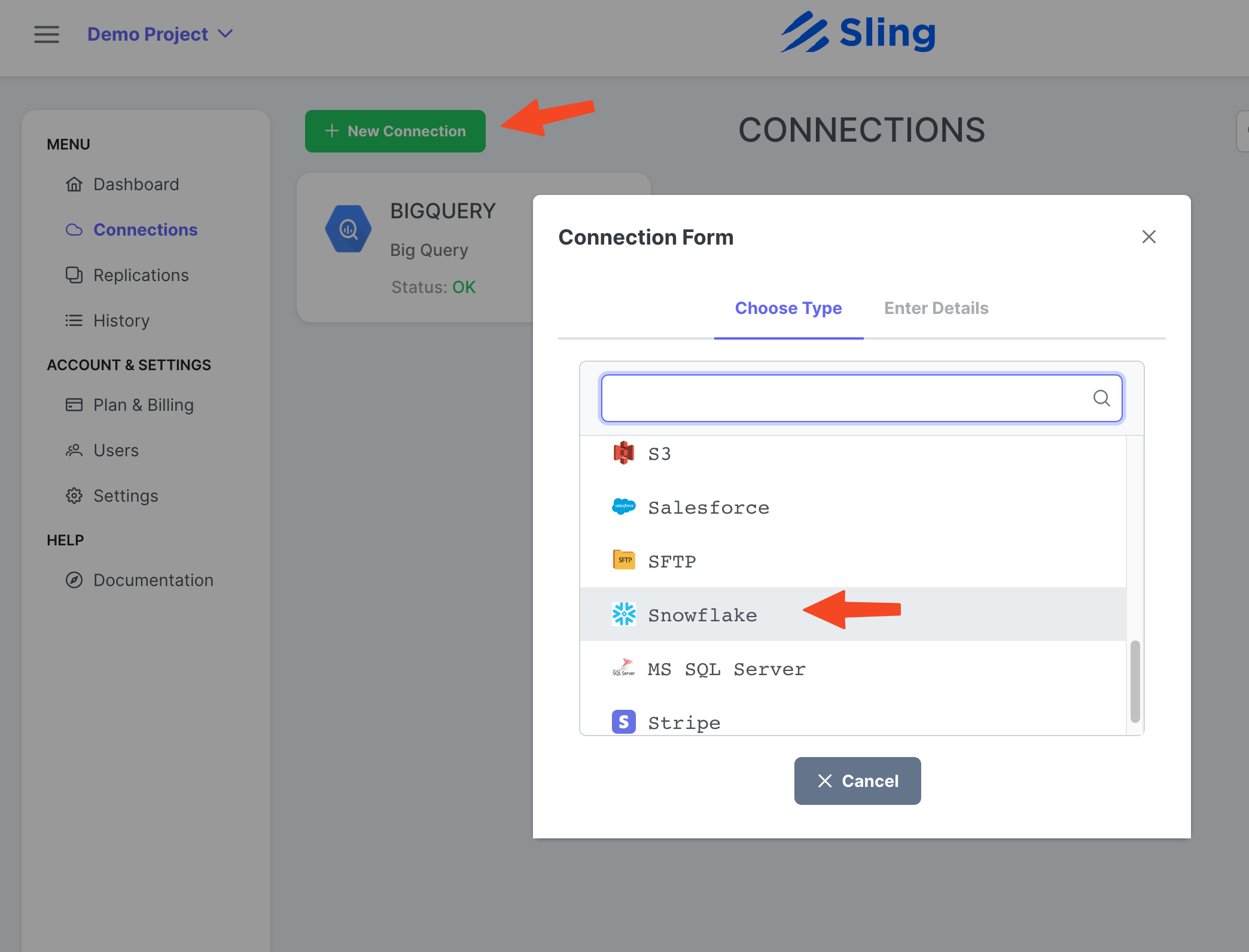
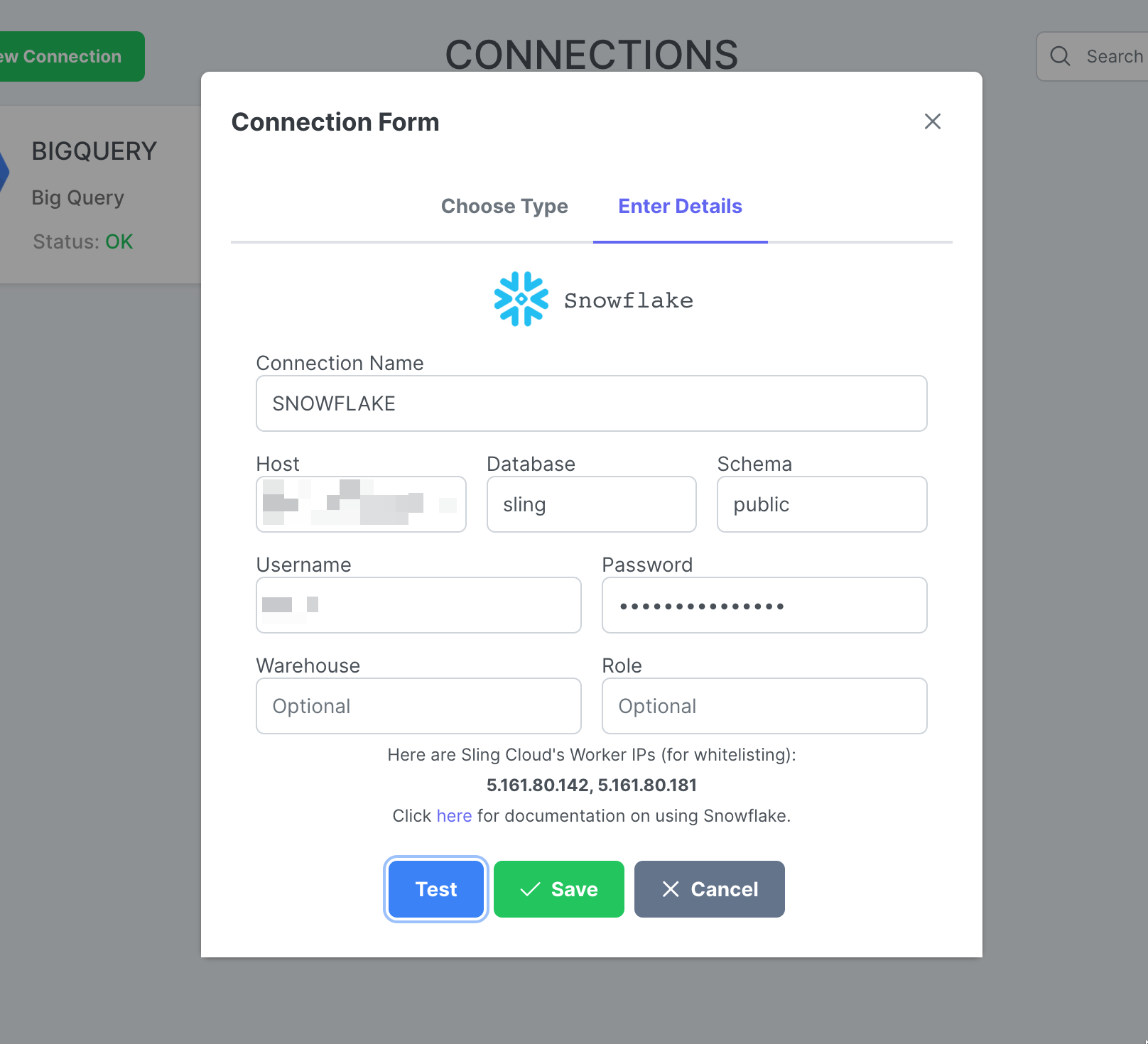
Haga clic en New Connection, seleccione Snowflake.
Introduzca el nombre SNOWFLAKE y sus credenciales. Haga clic en Test para probar la conectividad, luego Save.
Crear replicación
Pasos con capturas de pantalla
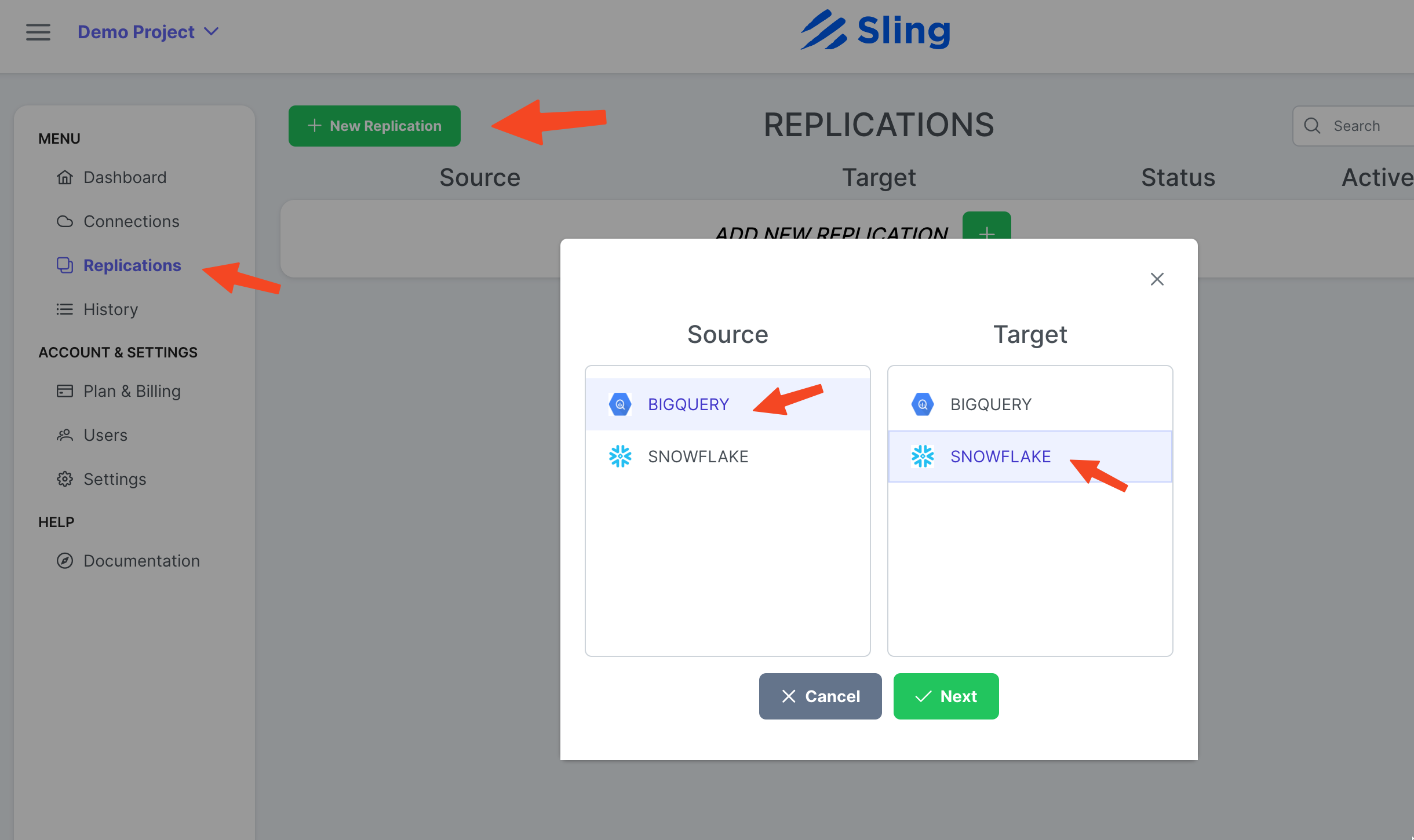
Vaya a Replications, haga clic en New Replication, seleccione Big Query como origen y Snowflake como destino. Haga clic en Next.
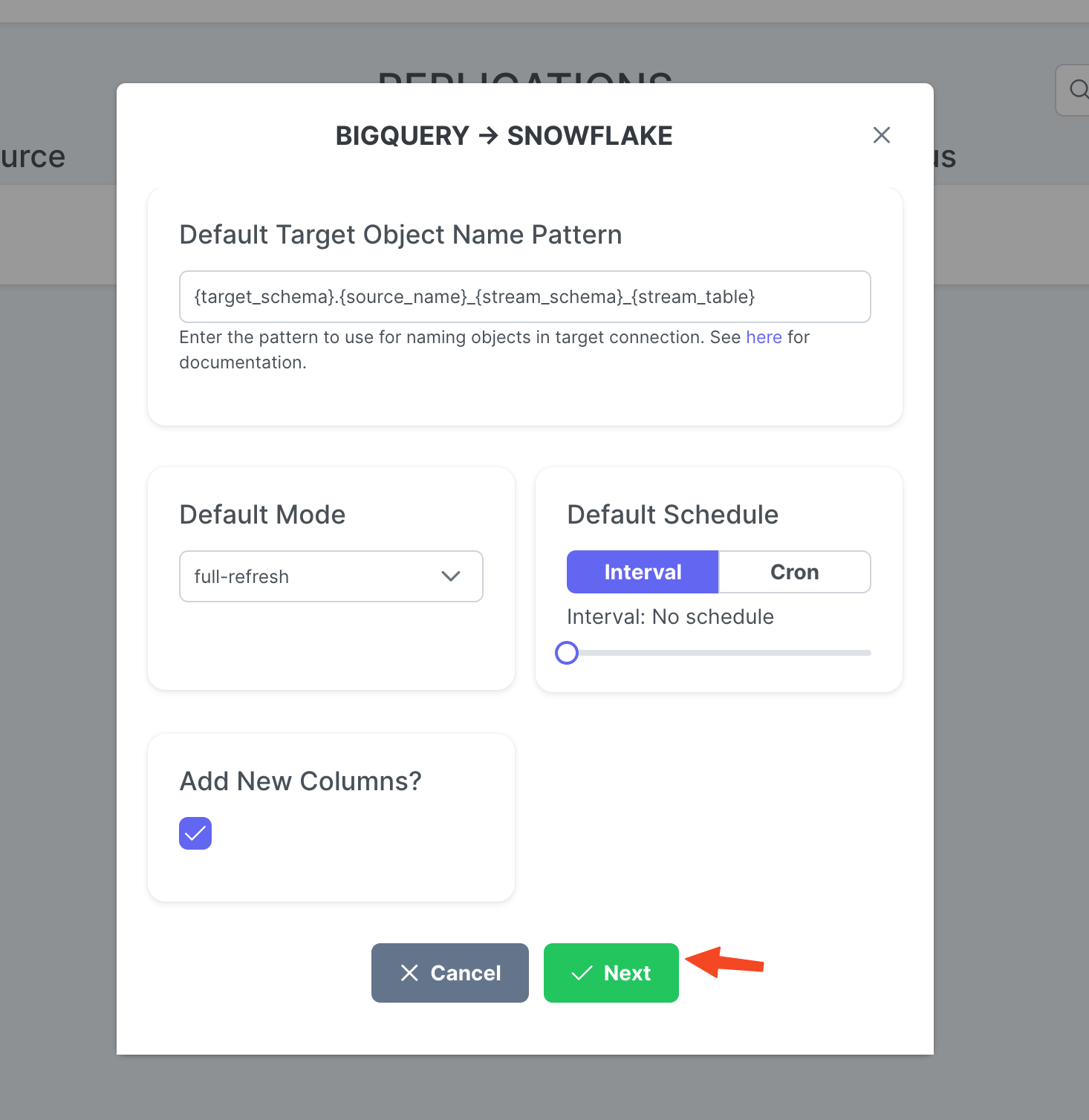
Ajuste a Target Object Name Pattern si lo desea y haga clic en Create.
Crear y ejecutar tarea
Pasos con capturas de pantalla
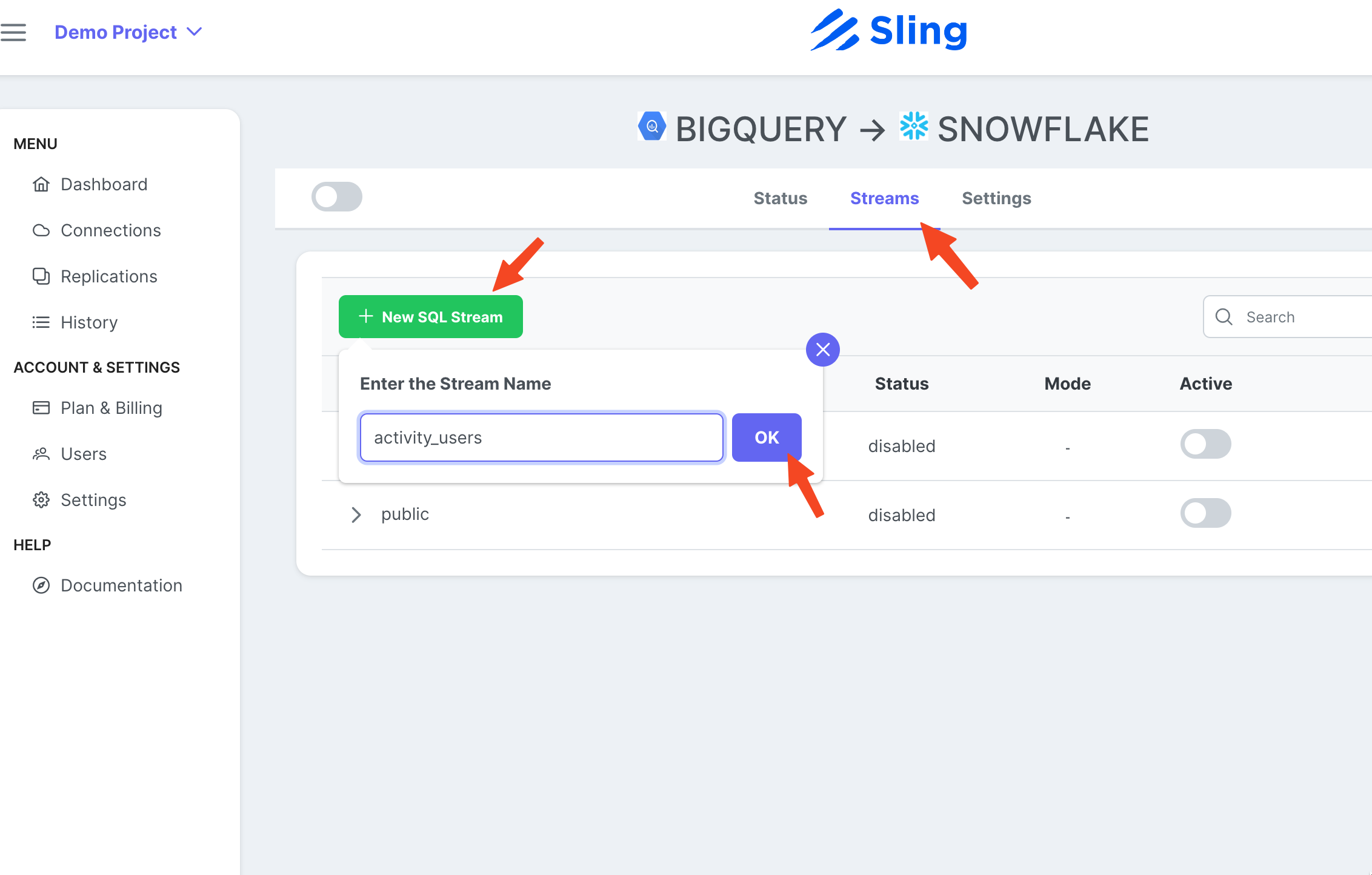
Vaya a la pestaña Streams, haga clic en New SQL Stream ya que estamos usando un SQL personalizado como fuente de datos. Dale un nombre (activity_user). Pegue la consulta SQL, haga clic en Ok.

Ahora que tenemos una tarea de transmisión lista, podemos presionar el ícono Reproducir para activarla.
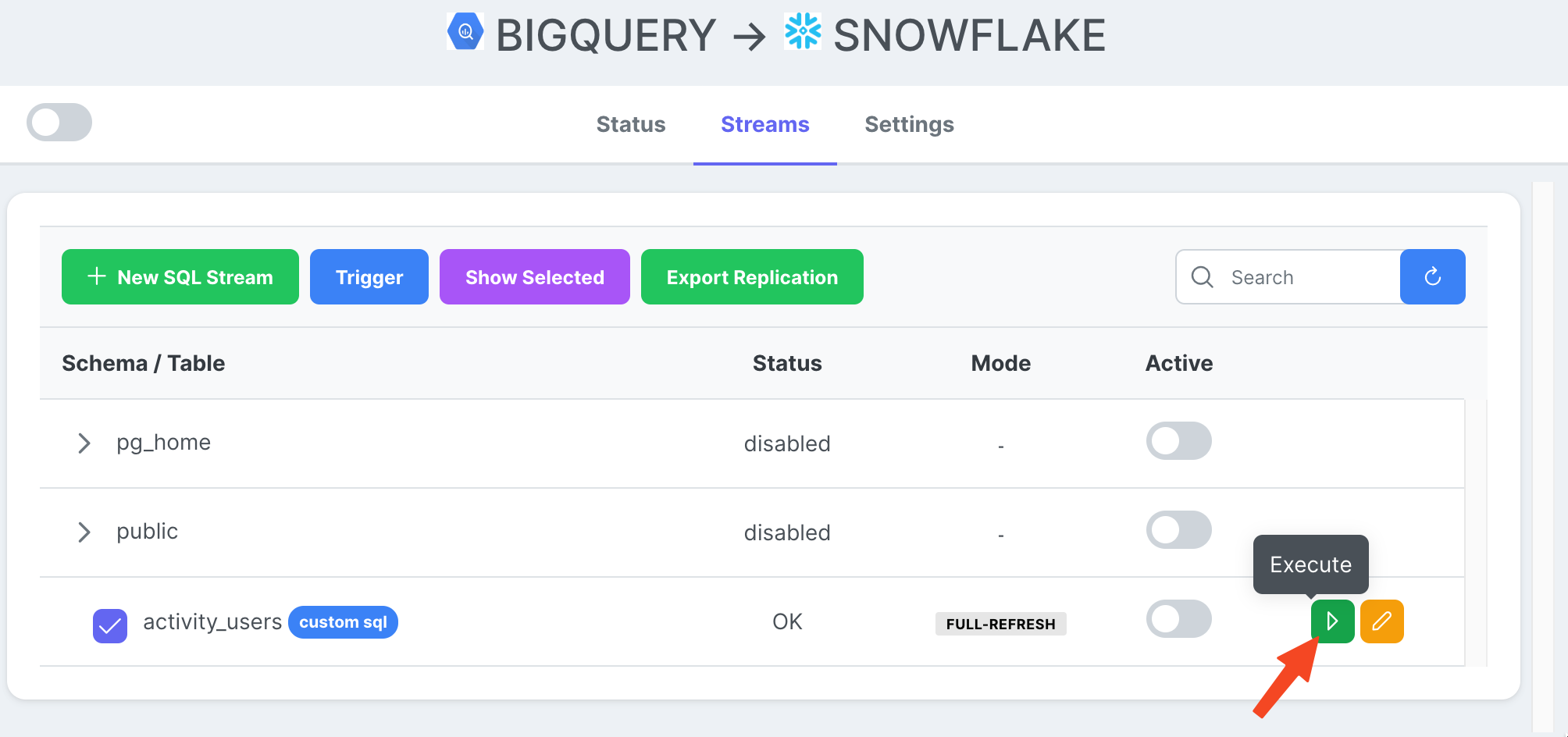
Una vez que se completa la ejecución de la tarea, podemos inspeccionar los registros.
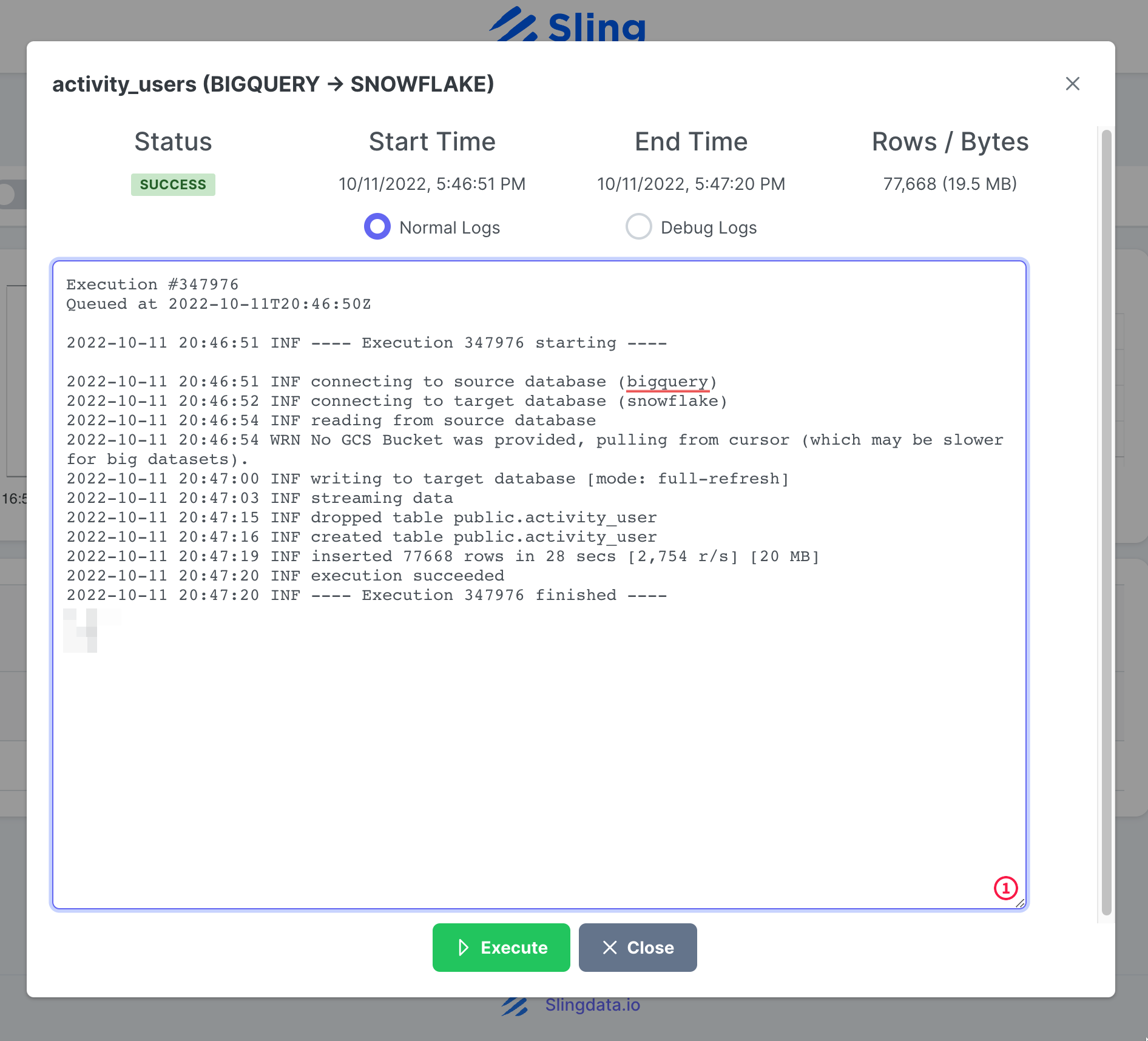
Eso es! Tenemos nuestra configuración de tareas y podemos volver a ejecutarla a pedido o configurarla en un horario. Como puede notar, Sling Cloud maneja algunas cosas más por nosotros y brinda a los usuarios orientados a la interfaz de usuario una mejor experiencia en comparación con Sling CLI.
Conclusión
Estamos en una era en la que los datos son oro, y mover datos de una plataforma a otra no debería ser difícil. Como hemos demostrado, Sling ofrece una poderosa alternativa al reducir la fricción asociada con la integración de datos. Cubriremos cómo exportar desde Snowflake y cargar en BigQuery en otra publicación.