
云数据仓库
在过去几年中,我们看到云数据仓库(以及“仓库优先”范式)的使用快速增长。两个流行的云 DWH 平台是 BigQuery 和 Snowflake。查看下面的图表,了解它们随时间的演变。
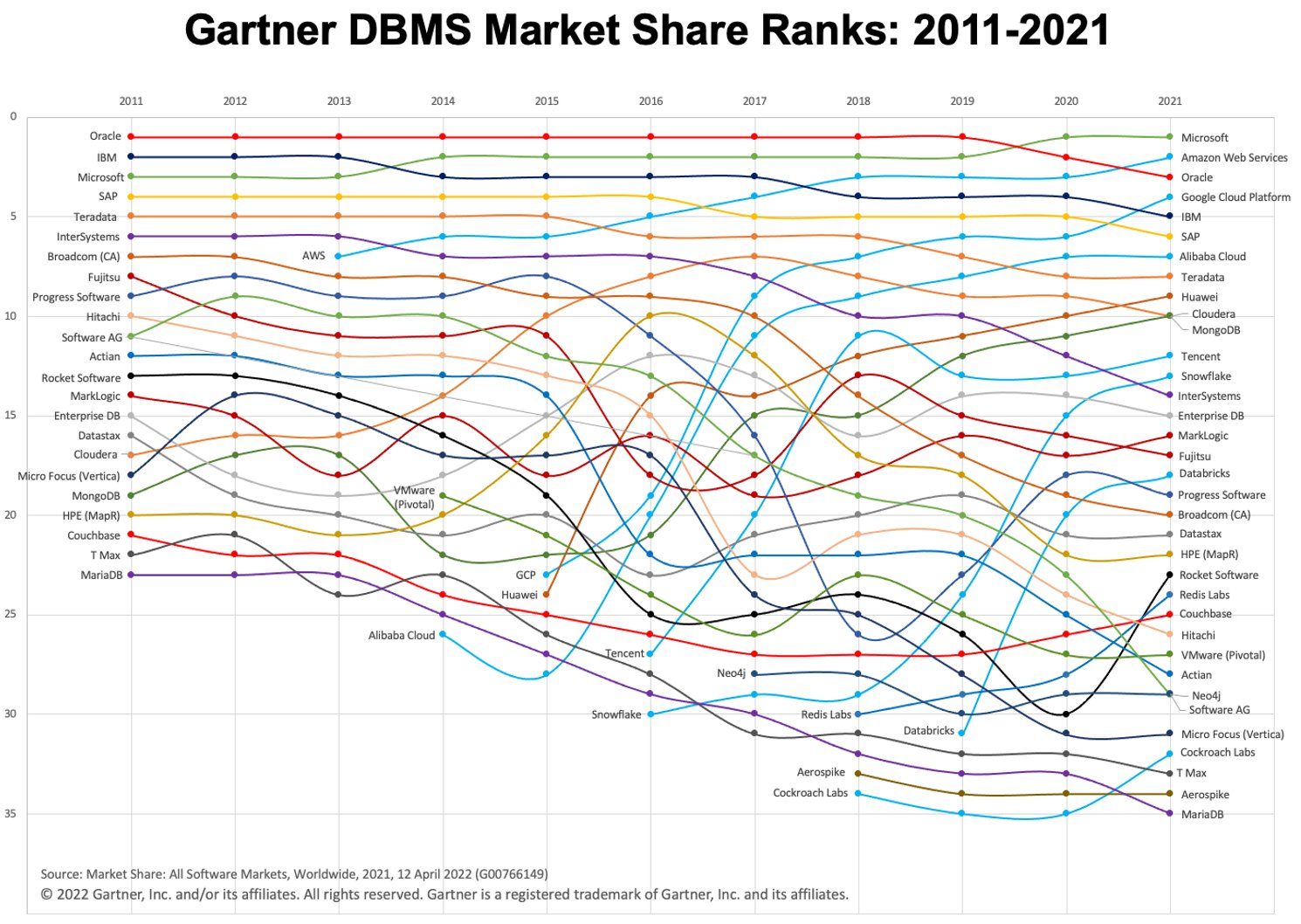 图片:Gartner 来自 Twitter 上的 Adam Ronthal (@aronthal)。
图片:Gartner 来自 Twitter 上的 Adam Ronthal (@aronthal)。
BigQuery,截至 2021 年排名第 4,是由 Google Cloud Platform (GCP) 提供的完全托管的无服务器数据仓库服务。它可以对 PB 级数据进行简单且可扩展的分析,并且长期以来一直以其易用性和免维护特性而闻名。
Snowflake 是 Snowflake Inc. 公司提供的一项类似服务。主要区别之一是 Snowflake 允许您在 Amazon Web Services (AWS)、Azure (Microsoft) 或 GCP (Google) 中托管实例。如果您已经在非 GCP 环境中建立,这是一个很大的优势。
导出和加载数据
根据情况,有时需要或希望将数据从 BigQuery 环境复制到 Snowflake 环境中。让我们看一下并分解正确移动此数据所需的各种逻辑步骤,因为竞争服务都没有集成功能来轻松完成此操作。为了我们的示例,我们将假设我们的目标 Snowflake 环境托管在 AWS 上。
逐步程序
为了将数据从 BigQuery 迁移到 Snowflake (AWS),以下是基本步骤:
识别表或查询并执行
EXPORT DATA OPTIONS查询以导出到 Google Cloud Storage (GCS)。在VM或本地机器上运行脚本将GCS数据复制到Snowflake的Internal Stage。我们也可以通过存储集成直接从 GCS 读取数据,但这涉及另一层安全访问配置(这可能更适合您的用例)。
手动生成具有正确列数据类型的
CREATE TABLEDDL 并在 Snowflake 中执行。在 Snowflake 中执行
COPY查询以导入暂存文件。可选择清理(删除)GCP 和内部阶段中的临时数据。
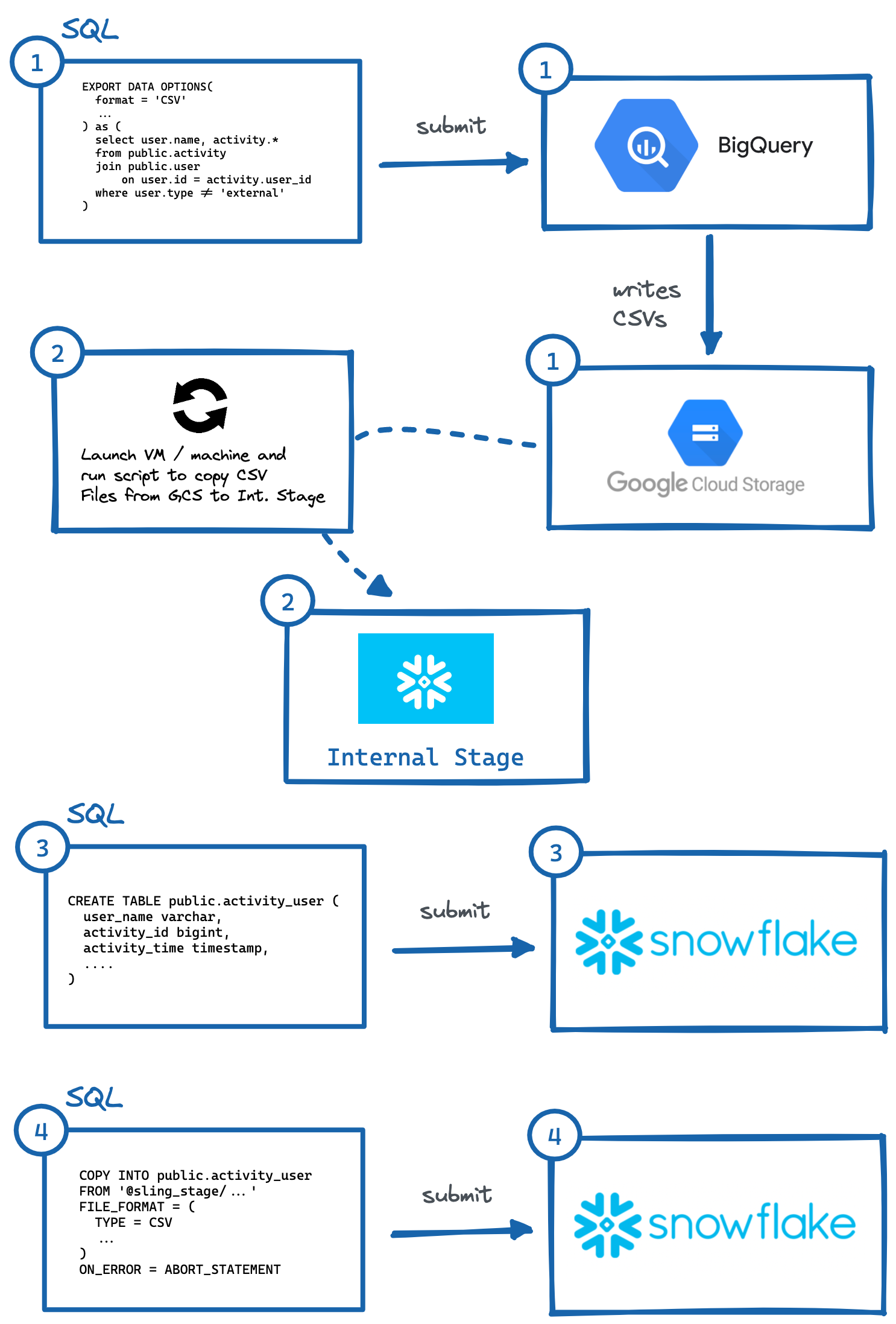 图片:从 BigQuery 手动导出到 Snowflake 的步骤。
图片:从 BigQuery 手动导出到 Snowflake 的步骤。如上所示,有几个步骤可以实现这一点,其中需要与独立系统进行交互。这对于自动化来说可能很麻烦,尤其是在目标系统中使用正确的列类型生成正确的 DDL(#3)(我个人认为这是最繁重的,请尝试对具有 50 多列的表执行此操作)。
幸运的是,有一种更简单的方法可以做到这一点,那就是使用一个名为 Sling 的漂亮工具。 Sling 是一种数据集成工具,可以轻松高效地从/向数据库、存储平台和 SaaS 应用程序移动数据(提取和加载)。有两种使用方式:Sling CLI 和 Sling Cloud。我们将执行与上述相同的过程,但仅通过向 sling 提供输入,它会自动为我们执行复杂的步骤!
使用 Sling CLI
如果您是命令行狂热者,Sling CLI 适合您。它内置在 go 中(这使得它超级快),并且它适用于文件、数据库和各种 saas 端点。它还可以与 Unix Pipes 一起使用(读取标准输入并写入标准输出)。我们可以从我们的 shell 中快速安装它:
# 在 Mac 上
brew install slingdata-io/sling/sling
# 在 Windows Powershell 上
scoop bucket add org https://github.com/slingdata-io/scoop-sling.git
scoop install sling
# 通过 pip 使用 Python Wrapper
pip install sling
有关其他安装选项(包括 Linux),请参阅 此处。还有一个 Python 包装器 库,如果您更喜欢在 Python 中与 Sling 交互,它会很有用。
安装后,我们应该能够运行 sling 命令,它应该给我们这样的输出:
sling - An Extract-Load tool | https://slingdata.io/zh
Slings data from a data source to a data target.
Version 0.86.52
Usage:
sling [conns|run|update]
Subcommands:
conns Manage local connections
run Execute an ad-hoc task
update Update Sling to the latest version
Flags:
--version Displays the program version string.
-h --help Displays help with available flag, subcommand, and positional value parameters.
现在有很多方法可以配置任务,但是对于本文的范围,我们首先需要为 BigQuery 和 Snowflake 添加连接凭据(一次性的家务)。我们可以通过打开文件 ~/.sling/env.yaml 并添加凭据来做到这一点,它应该如下所示:
~/.sling/env.yaml
connections:
BIGQUERY:
type: bigquery
project: sling-project-123
location: US
dataset: public
gc_key_file: ~/.sling/sling-project-123-ce219ceaef9512.json
gc_bucket: sling_us_bucket # this is optional but recommended for bulk export.
SNOWFLAKE:
type: snowflake
username: fritz
password: my_pass23
account: abc123456.us-east-1
database: sling
schema: public
太好了,现在让我们测试我们的连接:
$ sling conns list
+------------+------------------+-----------------+
| CONN NAME | CONN TYPE | SOURCE |
+------------+------------------+-----------------+
| BIGQUERY | DB - Snowflake | sling env yaml |
| SNOWFLAKE | DB - PostgreSQL | sling env yaml |
+------------+------------------+-----------------+
$ sling conns test BIGQUERY
6:42PM INF success!
$ sling conns test SNOWFLAKE
6:42PM INF success!
太棒了,现在我们已经建立了连接,我们可以运行我们的任务:
$ sling run --src-conn BIGQUERY --src-stream "select user.name, activity.* from public.activity join public.user on user.id = activity.user_id where user.type != 'external'" --tgt-conn SNOWFLAKE --tgt-object 'public.activity_user' --mode full-refresh
11:37AM INF connecting to source database (bigquery)
11:37AM INF connecting to target database (snowflake)
11:37AM INF reading from source database
11:37AM INF writing to target database [mode: full-refresh]
11:37AM INF streaming data
11:37AM INF dropped table public.activity_user
11:38AM INF created table public.activity_user
11:38AM INF inserted 77668 rows
11:38AM INF execution succeeded
哇,这很容易! Sling 自动完成了我们之前描述的所有步骤。我们甚至可以将 Snowflake 数据导出回我们的 shell sdtout(以 CSV 格式),只需为 public.activity_user 标志提供表标识符 (--src-stream) 并计算行数以验证我们的数据:
$ sling run --src-conn SNOWFLAKE --src-stream public.activity_user --stdout | wc -l
11:39AM INF connecting to source database (snowflake)
11:39AM INF reading from source database
11:39AM INF writing to target stream (stdout)
11:39AM INF wrote 77668 rows
11:39AM INF execution succeeded
77669 # CSV output includes a header row (77668 + 1)
使用 Sling Cloud
现在让我们对 Sling Cloud 应用程序做同样的事情。 Sling Cloud 使用与 Sling CLI 相同的引擎,除了它是一个完全托管的平台,可以以有竞争力的价格运行您的所有 Extract-Load 需求(查看我们的 [定价页面](https://slingdata.io/zh/价钱))。使用 Sling Cloud,我们可以:
与许多团队成员合作
管理多个工作区/项目
安排提取加载 (EL) 任务以间隔或固定时间 (CRON) 运行
收集和分析日志以进行调试
通过电子邮件或 Slack 的错误通知
如果需要,可以从全球区域或自托管模式运行(其中 Sling Cloud 是协调器)。
用于快速设置和执行的直观用户界面 (UI)
首先是注册一个免费帐户 这里。登录后,我们可以选择
Cloud Mode(稍后将详细介绍Self-Hosted模式)。现在我们可以执行与上述类似的步骤,但使用 Sling Cloud UI:
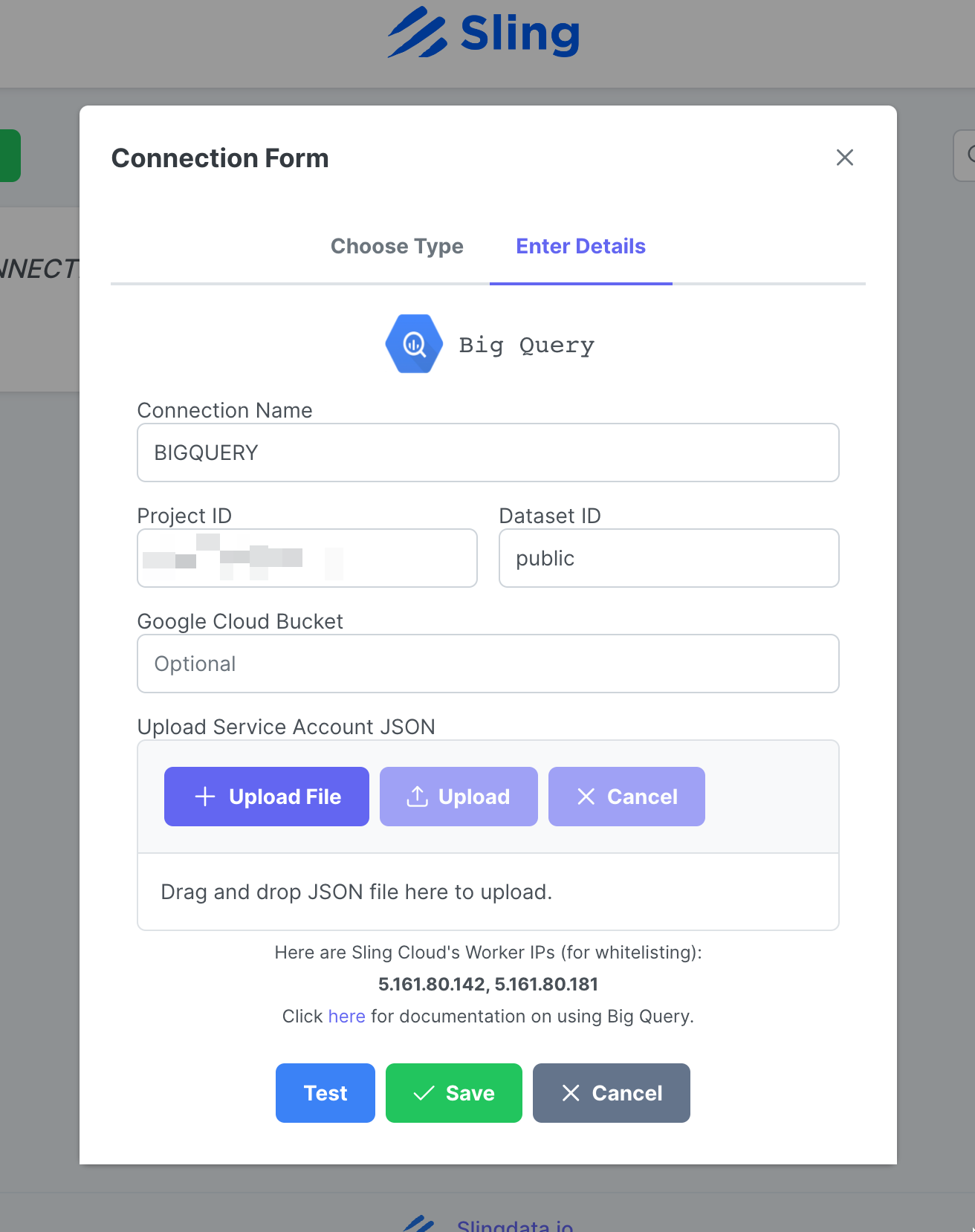
添加 BigQuery 连接
步骤截图
转到 Connections,单击 New Connection,选择 Big Query。

输入姓名 BIGQUERY、您的凭据,然后上传您的 google 帐户 JSON 文件。点击 Test 测试连接性,然后点击 Save。
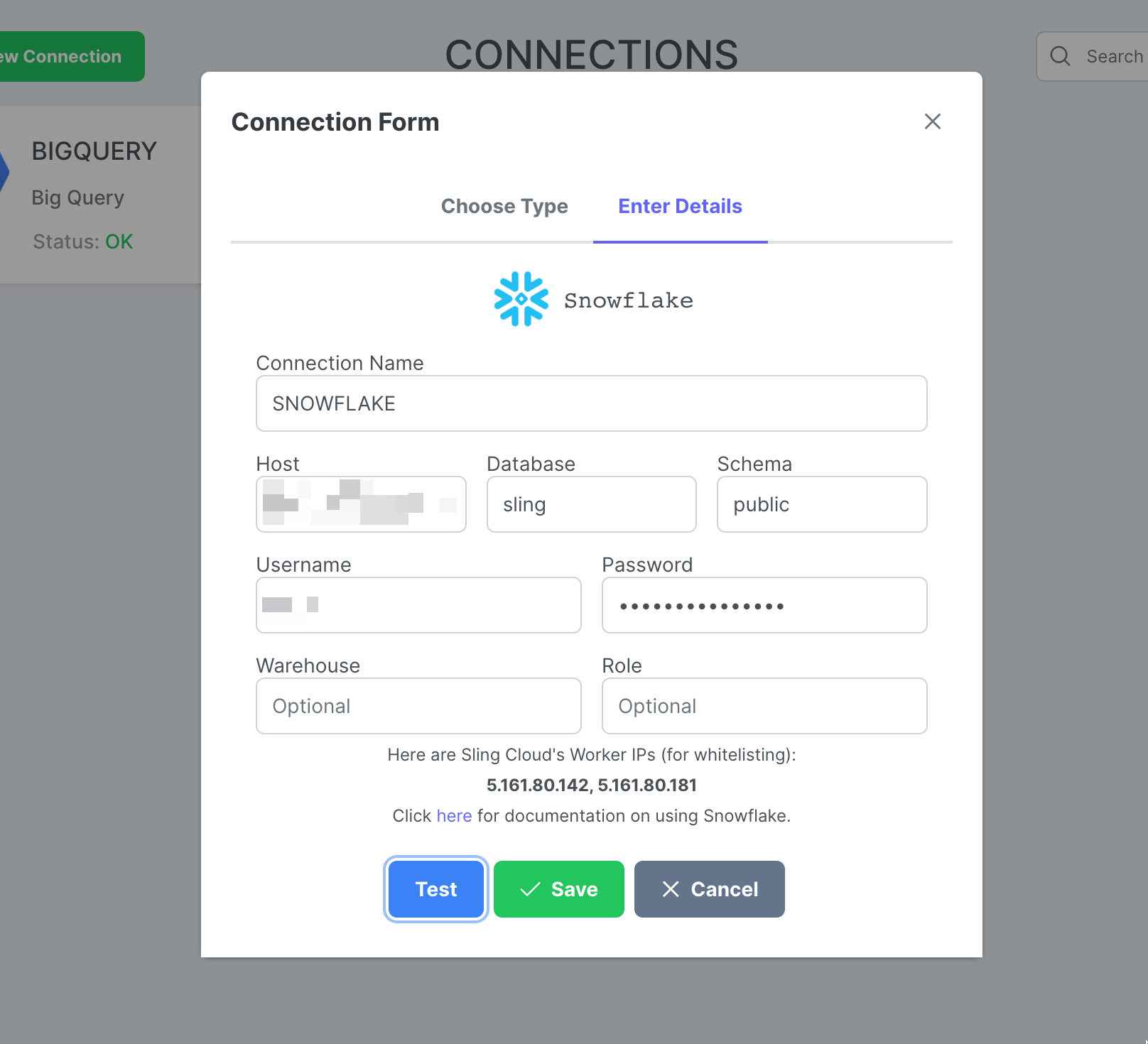
添加雪花连接
步骤截图
单击 New Connection,选择 Snowflake。
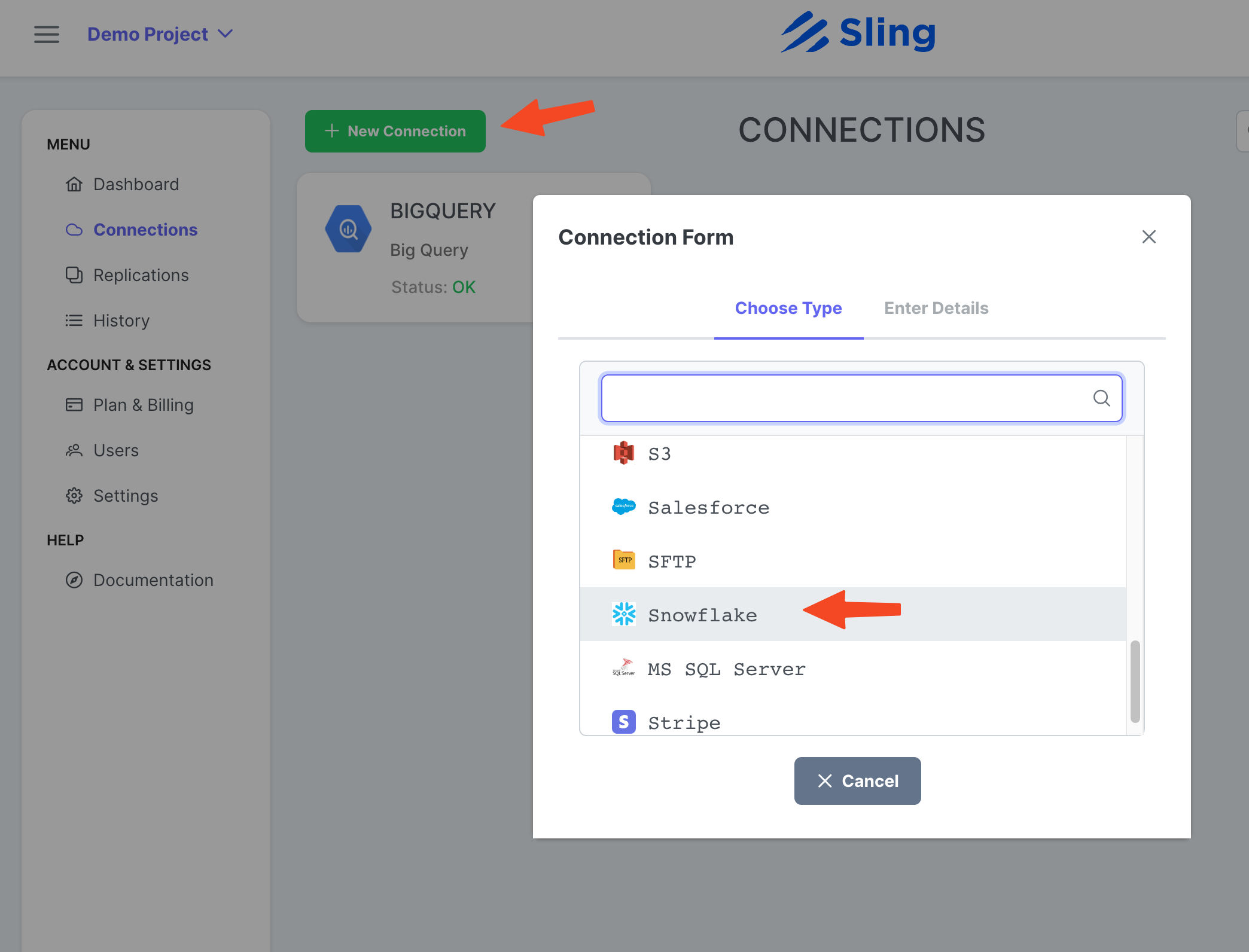
输入名称 SNOWFLAKE 和您的凭据。点击 Test 测试连接性,然后点击 Save。
创建复制
步骤截图
转到 Replications,单击 New Replication,选择 Big Query 作为源,选择 Snowflake 作为目标。点击 Next。
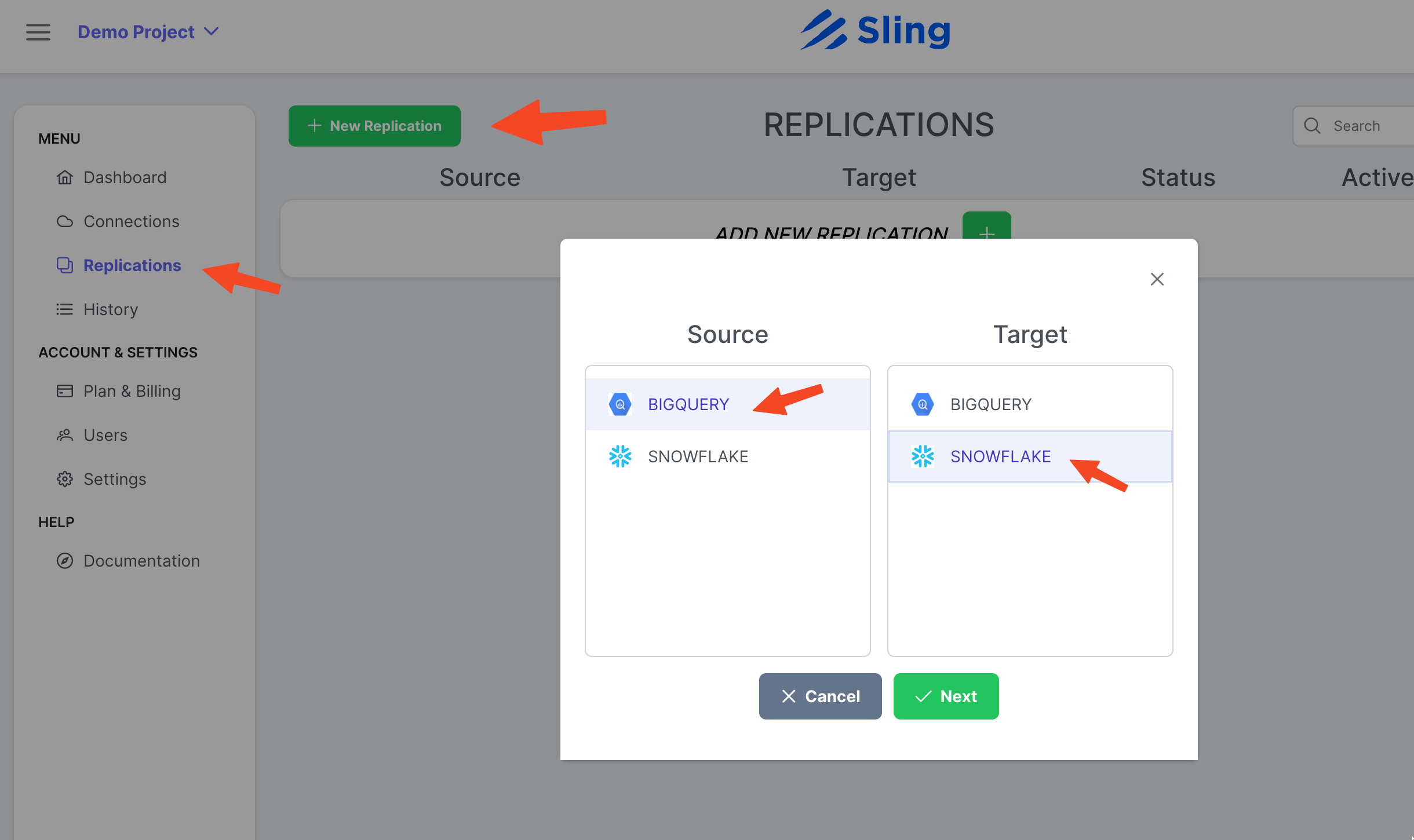
如果需要,调整为 Target Object Name Pattern,然后单击 Create。

创建并运行任务
步骤截图
转到 Streams 选项卡,单击 New SQL Stream,因为我们使用自定义 SQL 作为源数据。给它一个名字 (activity_user)。粘贴 SQL 查询,点击 Ok。


现在我们已经准备好一个流任务,我们可以点击播放图标来触发它。

一旦任务执行完成,我们可以检查日志。

就是这样!我们有我们的任务设置,我们可以按需重新运行它或按计划设置它。您可能会注意到,与 Sling CLI 相比,Sling Cloud 为我们处理了更多的事情,并为面向 UI 的用户提供了更好的体验。
结论
我们处在一个数据就是黄金的时代,将数据从一个平台转移到另一个平台应该不难。正如我们所展示的,Sling 通过减少与数据集成相关的摩擦提供了一种强大的替代方案。我们将在另一篇文章中介绍如何从 Snowflake 导出并加载到 BigQuery。